📘 源码阅读全流程
总览:12 阶段流程(Bird’s-eye)
- 目标与边界 →
- 背景取经(业务/技术/领域) →
- 仓库画像(规模/活跃度/分支/License) →
- 环境与运行(构建、启动、最小可复现) →
- 结构鸟瞰(模块图/依赖图/入口点) →
- 主线追踪(关键用户旅程/核心用例) →
- 数据与状态(模型/配置/存储/一致性) →
- 历史演化(Git log/PR/Issue/变更原因) →
- 非功能属性(性能/可靠性/安全/可运维) →
- 测试与可观测(测试金字塔/日志/指标/Trace) →
- 难点深潜(算法/协议/并发/异步/边界) →
- 验证与输出(实验/笔记/图谱/复盘/PR)
三种阅读深度与时间盒(建议)
- 快速上手(2–4 小时):阶段 1–4–6(跑起来 + 路径串起来)。
- 系统掌握(1–3 天):补齐 2、3、5、7、10、12。
- 专家精读(1–2 周):深挖 8、9、11。
阶段 1:目标与边界(Why / What / Stop Rule)
要点:先明确目标,设定停止条件
思考问题
- 我为什么要读这份代码?目标是什么?是学习新技术栈和框架或学习业务?是修复bug?还是改进和优化项目?
- 阅读该项目,可以学习到什么?
- 哪些目录/模块与目标最相关?哪些可以先忽略?
- 停止阅读条件是什么?
AI 提问模板
目标澄清
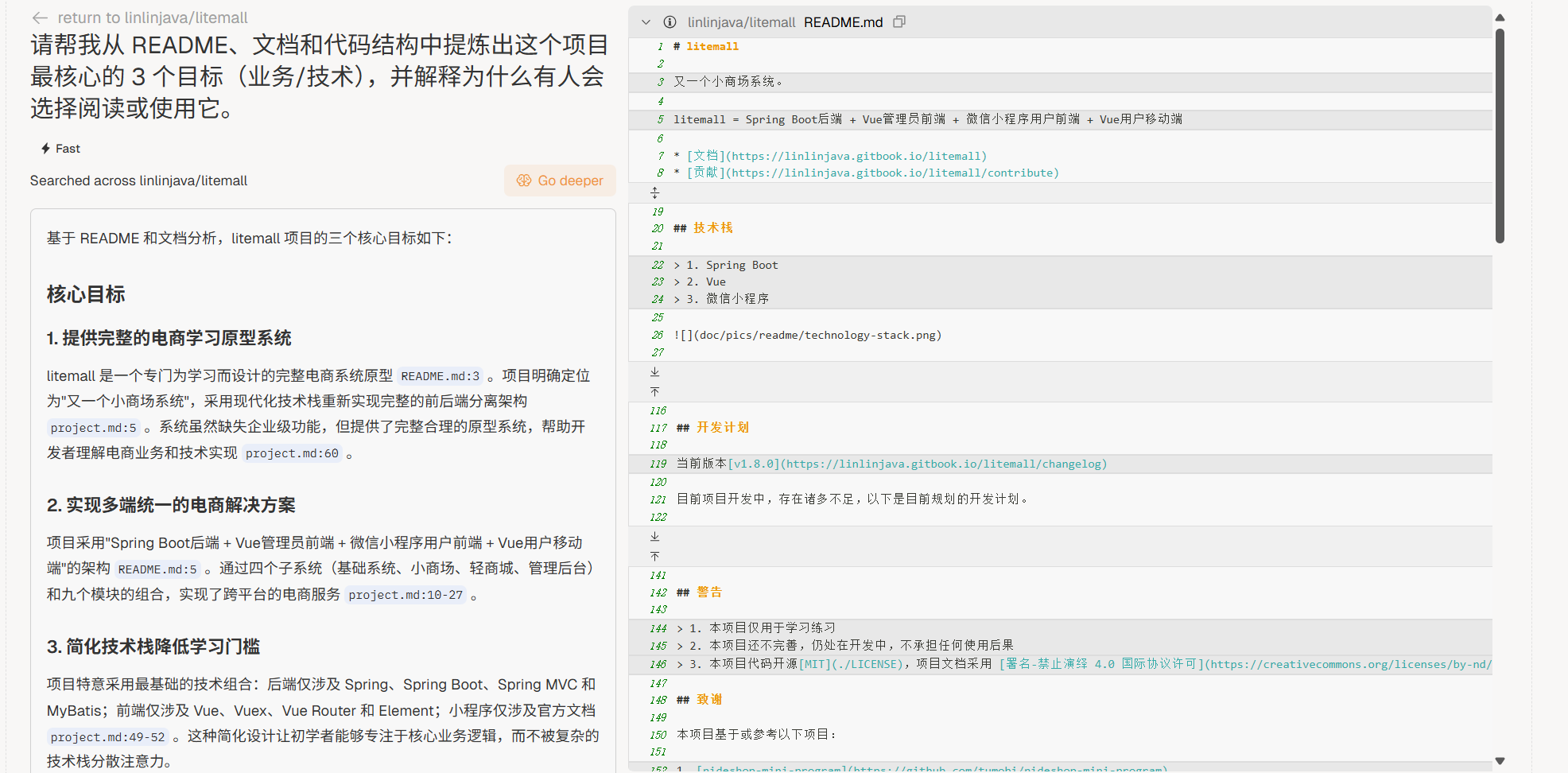
“请帮我从 README、文档和代码结构中提炼出这个项目最核心的 3 个目标(业务/技术),并解释为什么有人会选择阅读或使用它。”
学习价值
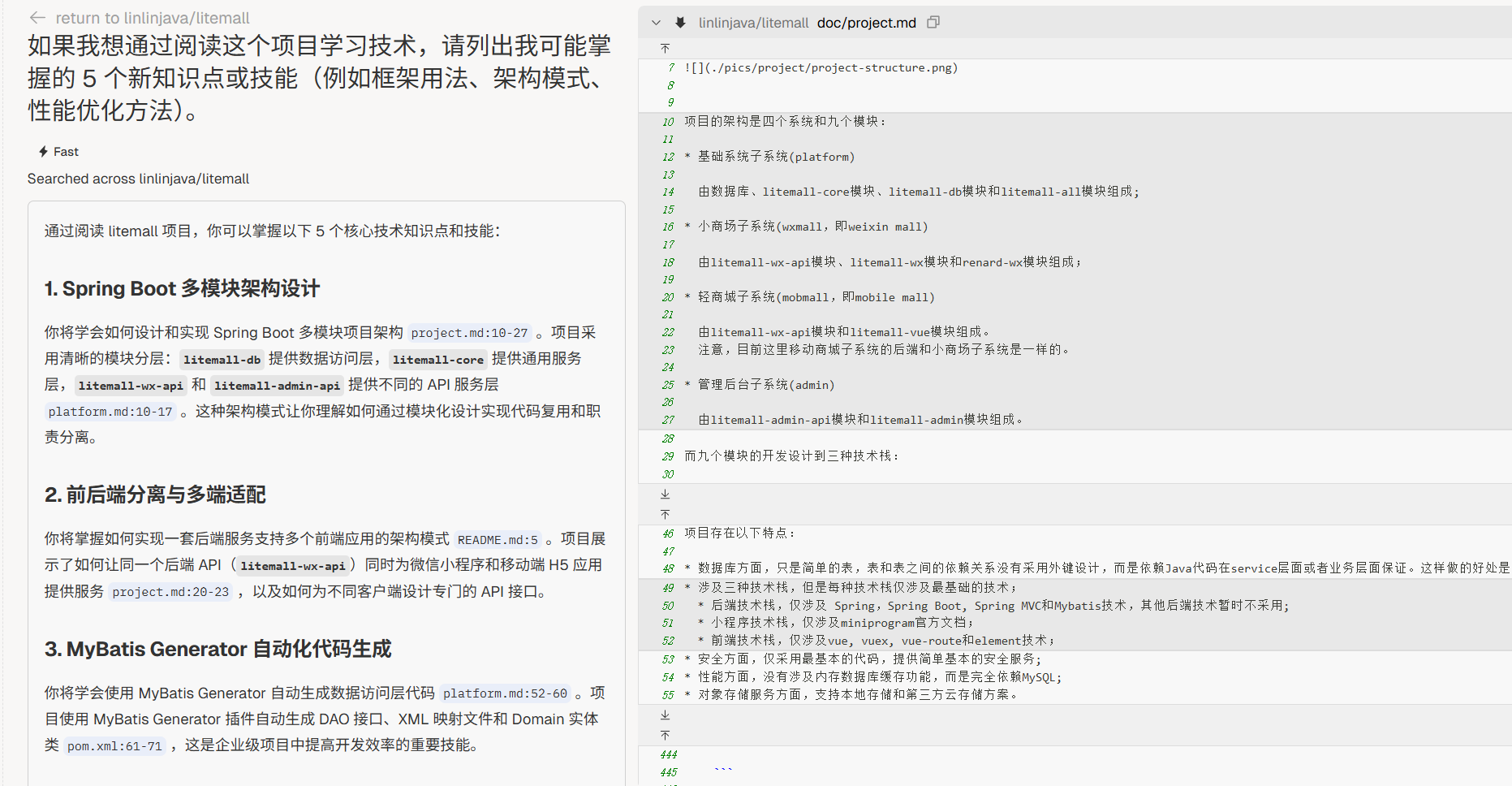
“如果我想通过阅读这个项目学习技术,请列出我可能掌握的 5 个新知识点或技能(例如框架用法、架构模式、性能优化方法)。”
范围聚焦
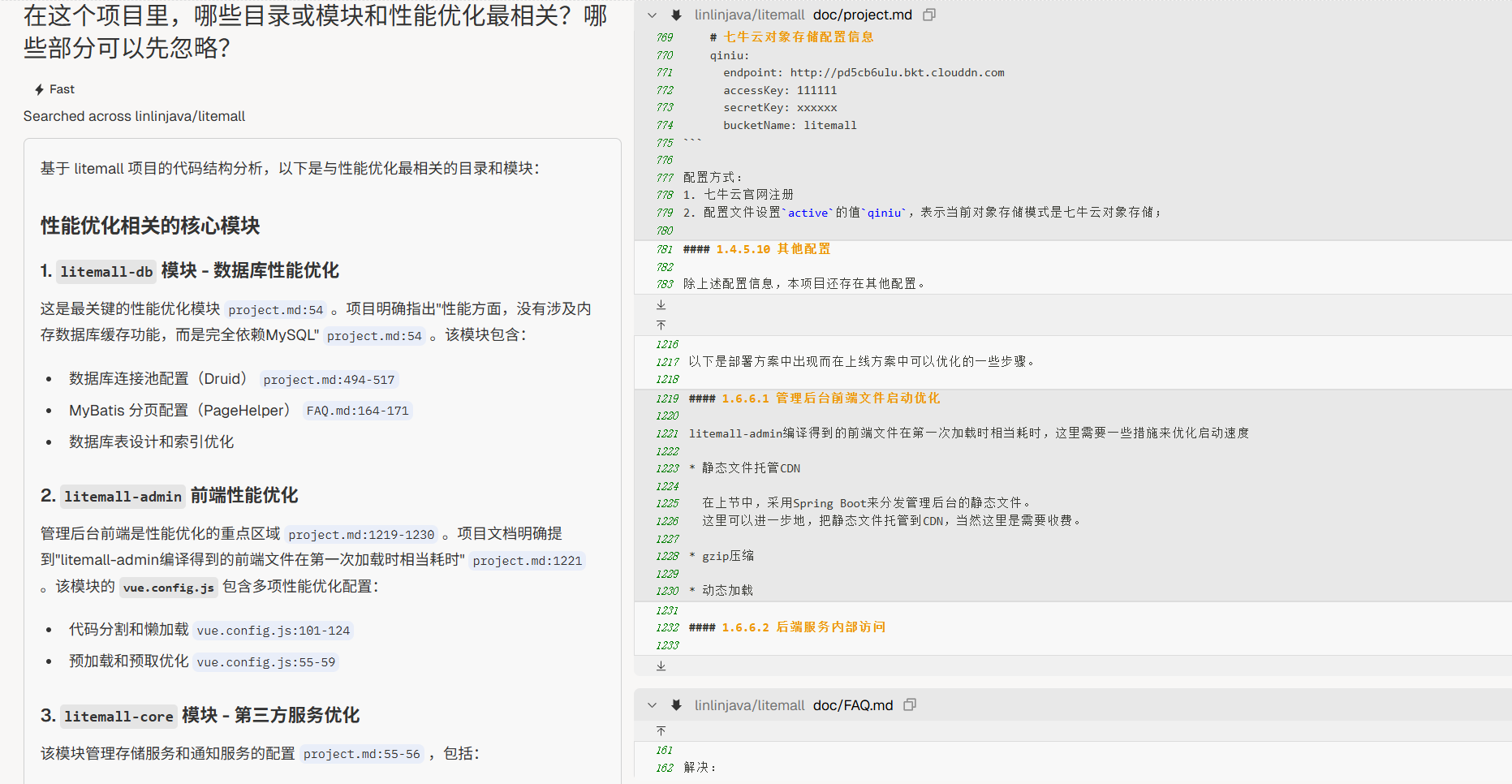
“在这个项目里,哪些目录或模块和 [我关注的目标,例如:性能优化 / Bug 修复 / 学习架构模式] 最相关?哪些部分可以先忽略?”
任务导向
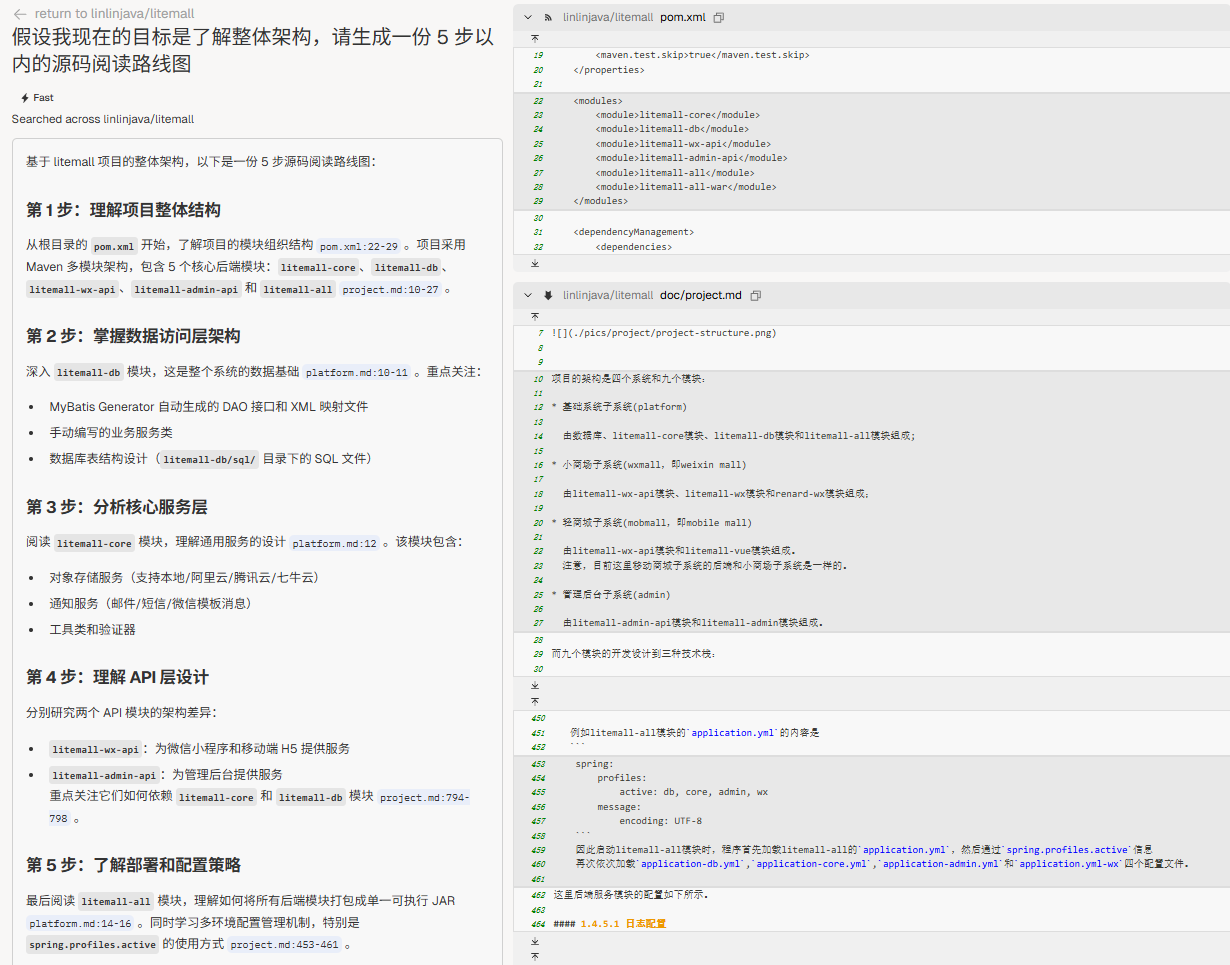
“假设我现在的目标是 [学习业务逻辑 / 修复一个具体的 bug / 了解整体架构],请生成一份 5 步以内的源码阅读路线图。”
停止条件
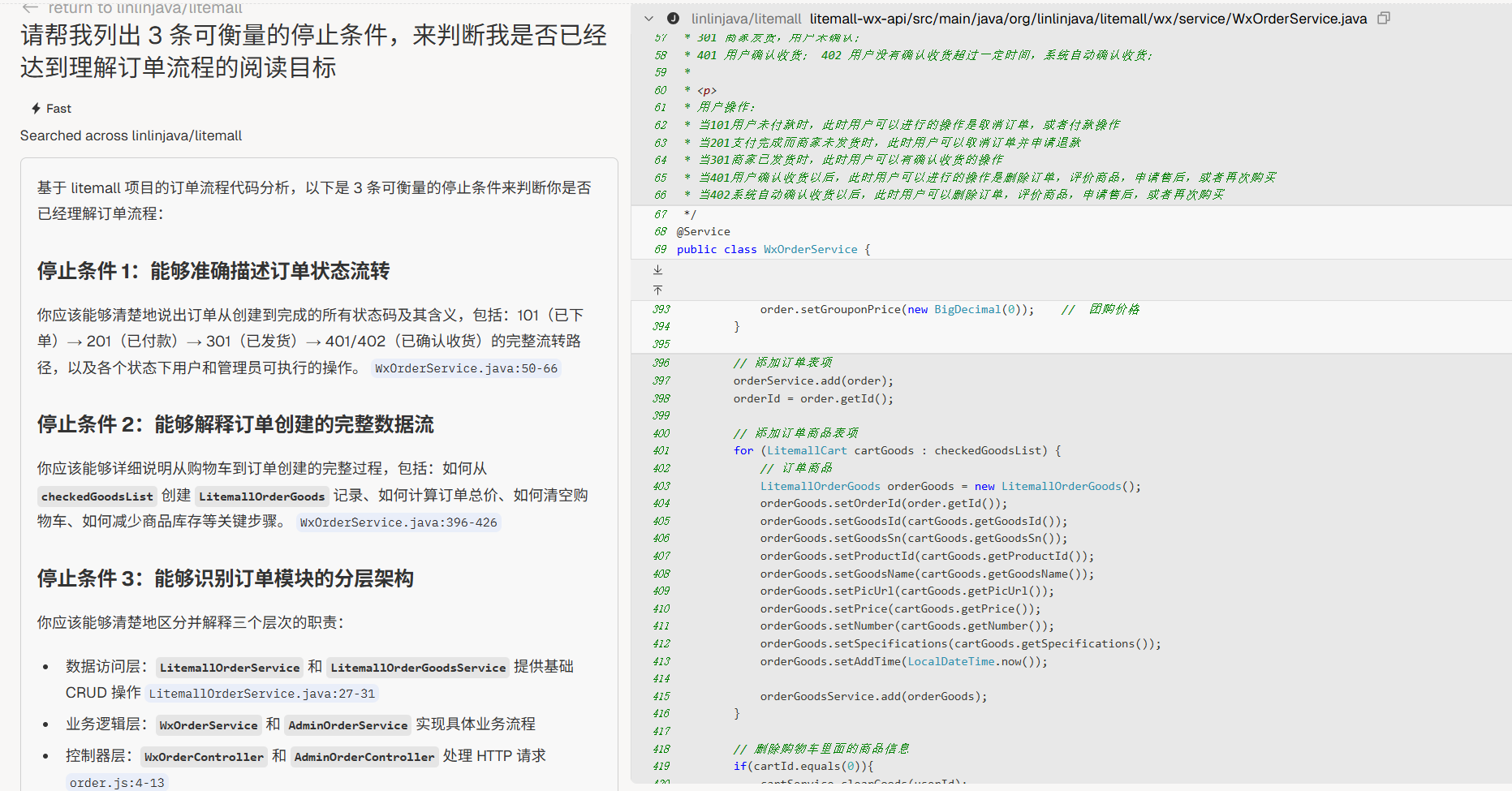
“请帮我列出 3 条可衡量的停止条件,来判断我是否已经达到 [我的阅读目标,例如:理解订单流程 / 掌握缓存机制]。”
案例
阶段 2:背景理解(Domain & Tech)
要点:理解业务和领域术语
思考问题
- 项目属于哪个技术/业务生态?阅读前需要补充掌握哪些技术/业务知识?
- 关键术语、模型、约束是什么?
- 架构风格:分层 / DDD / 微服务 / 插件化?
AI 提问模板
生态定位
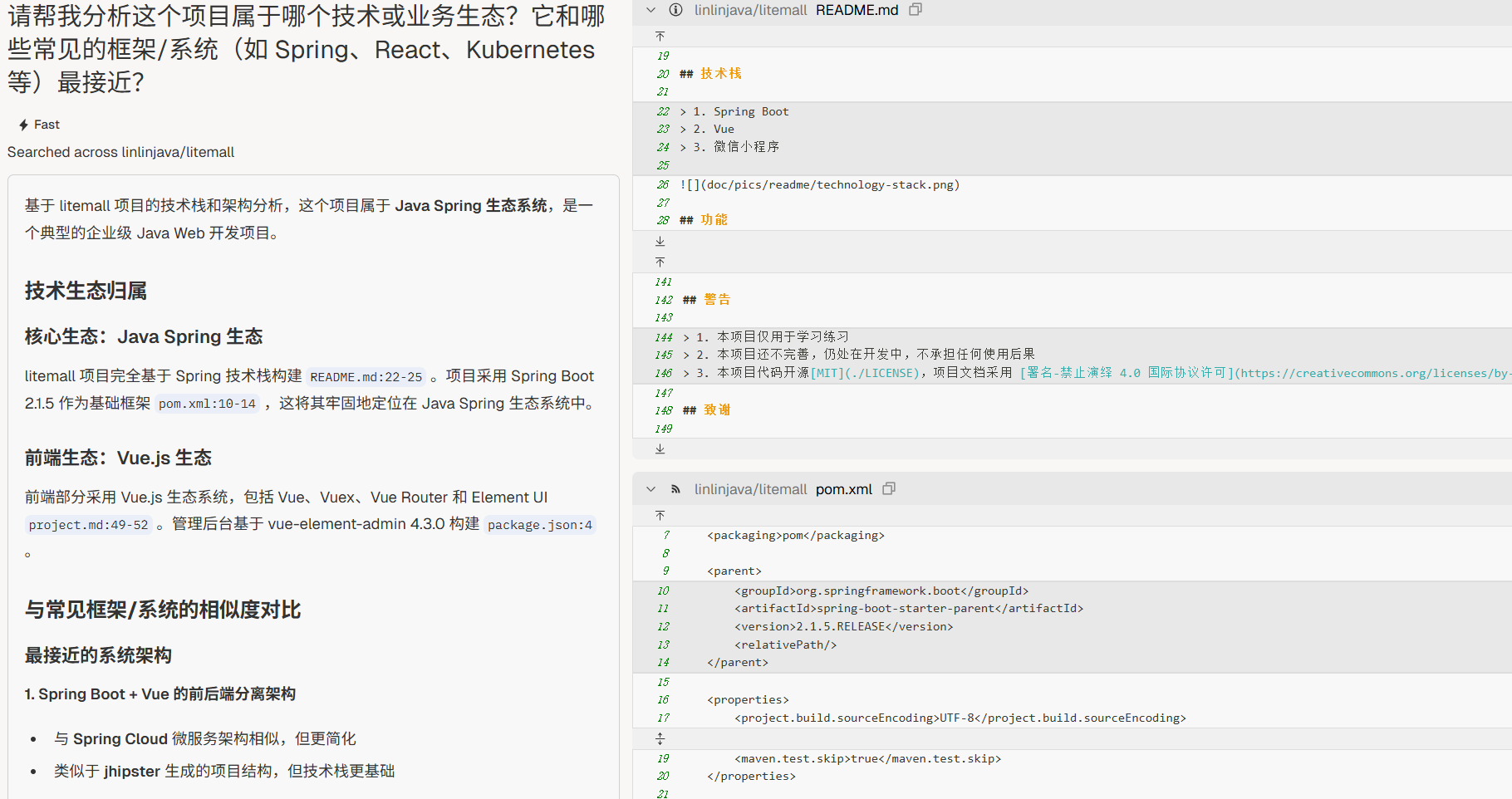
“请帮我分析这个项目属于哪个技术或业务生态?它和哪些常见的框架/系统(如 Spring、React、Kubernetes 等)最接近?”
术语速览
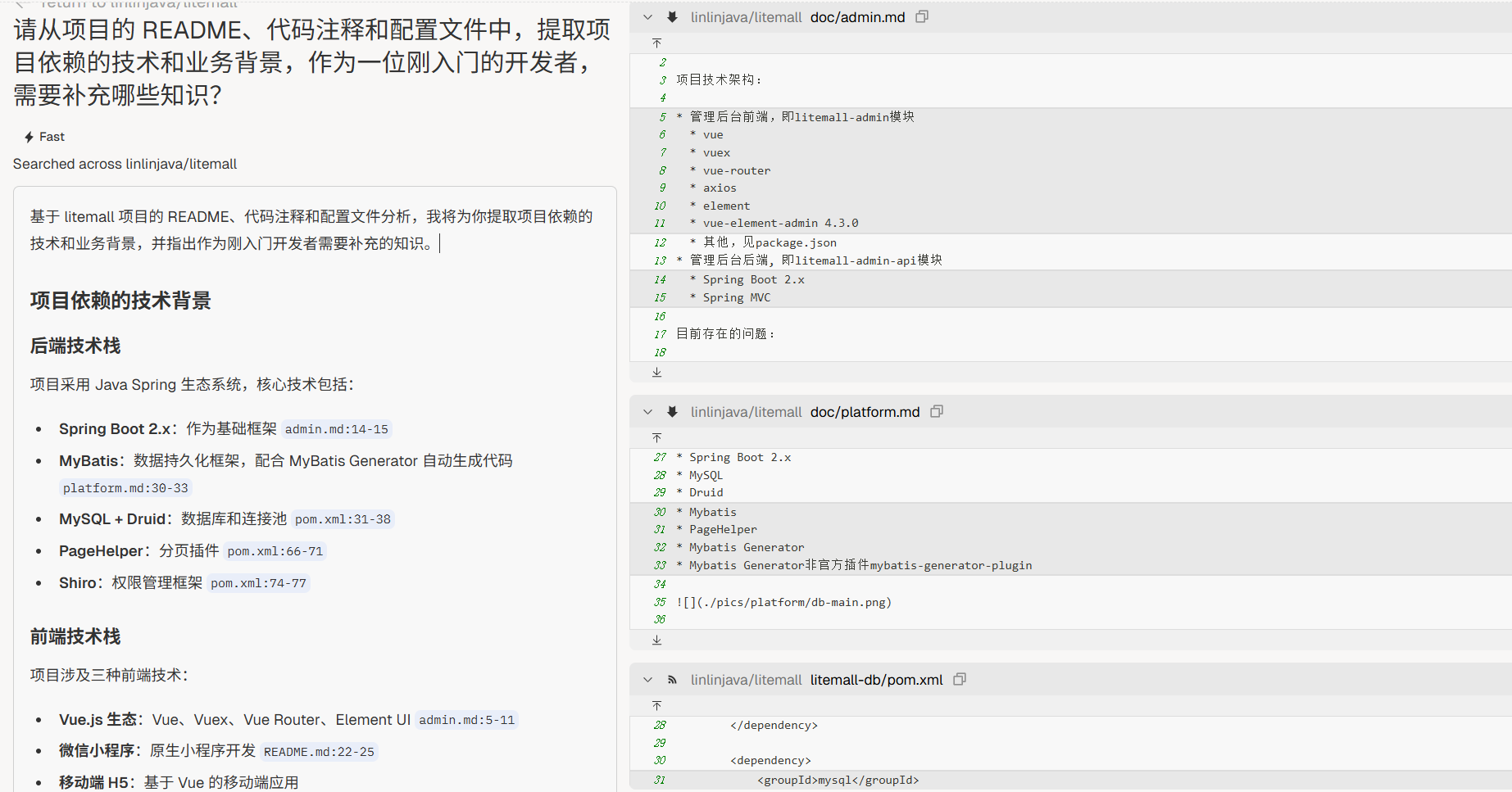
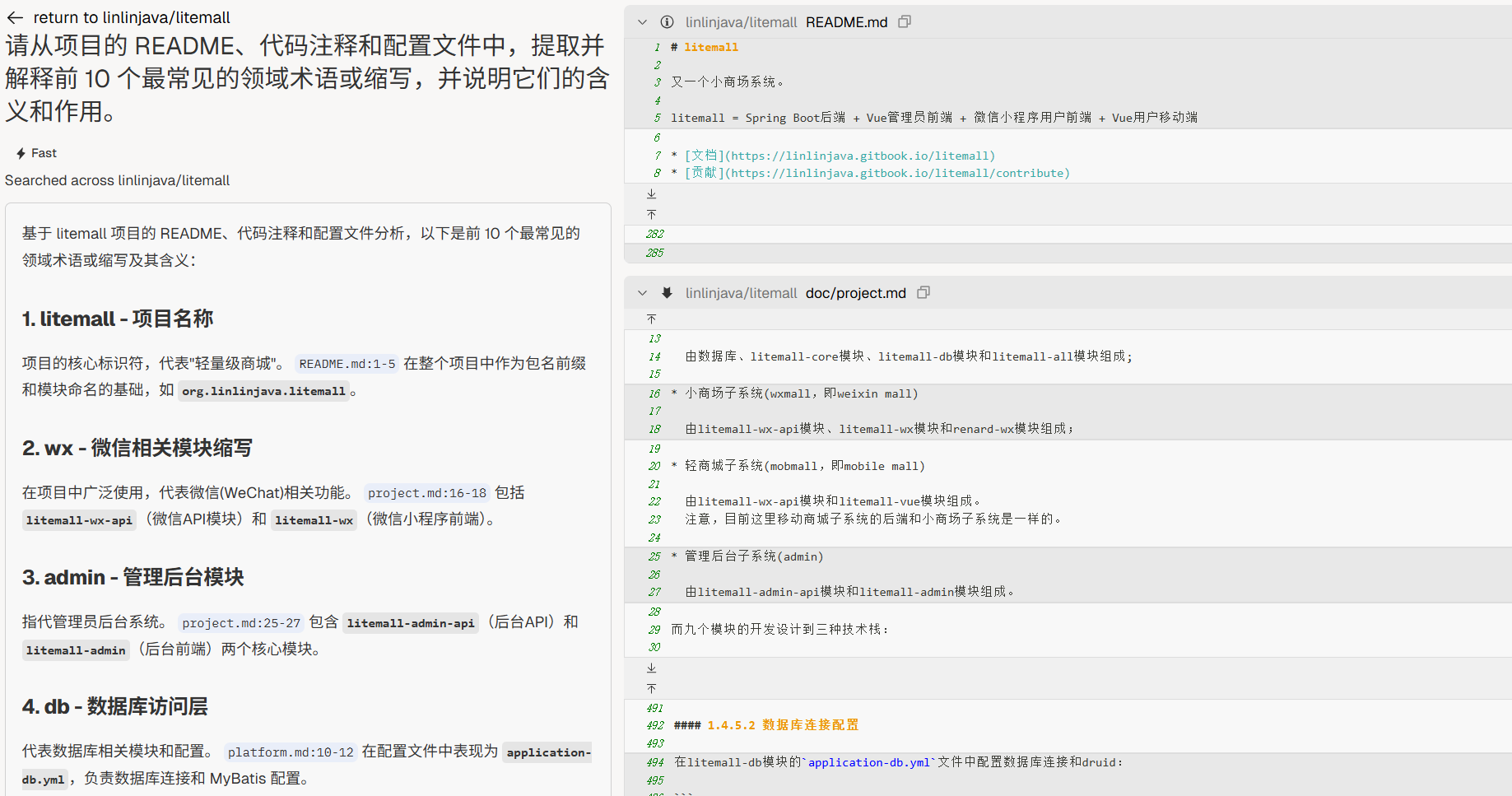
“请从项目的 README、代码注释和配置文件中,提取并解释前 10 个最常见的领域术语或缩写,并说明它们的含义和作用。”
业务模型理解
“根据源码和文档,请帮我画出(或用文字描述)项目的核心业务模型/数据模型,以及它们之间的关系。”
架构风格识别
“请判断这个项目采用了哪种架构风格(分层 / DDD / 微服务 / 插件化等),并给出你推断的依据(如目录结构、命名、依赖方式)。”
约束与边界
“请总结项目在业务和技术上的关键约束条件(例如:必须保持强一致性、需要支持水平扩展、依赖特定中间件),这些约束如何影响代码设计?”
案例
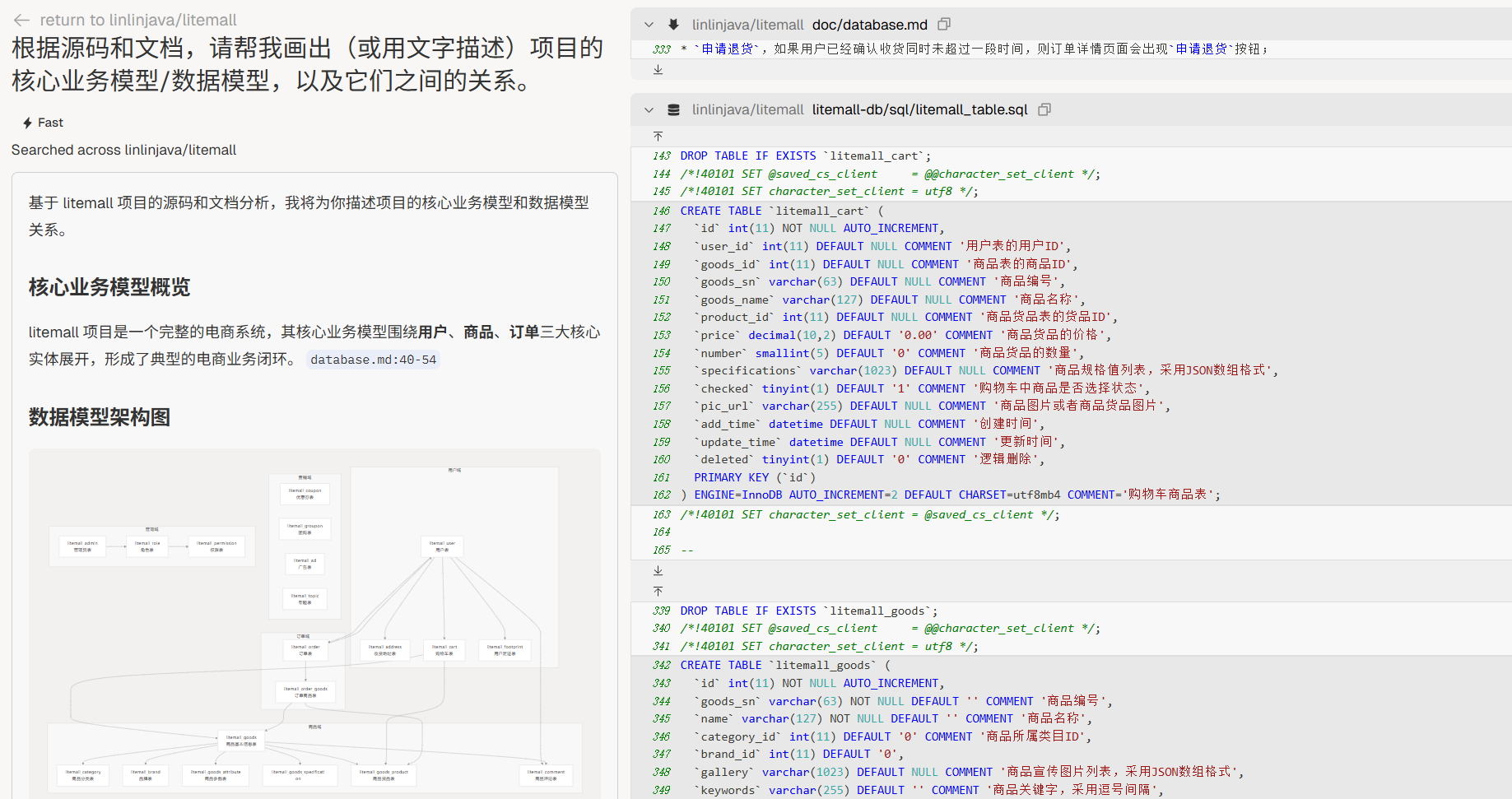
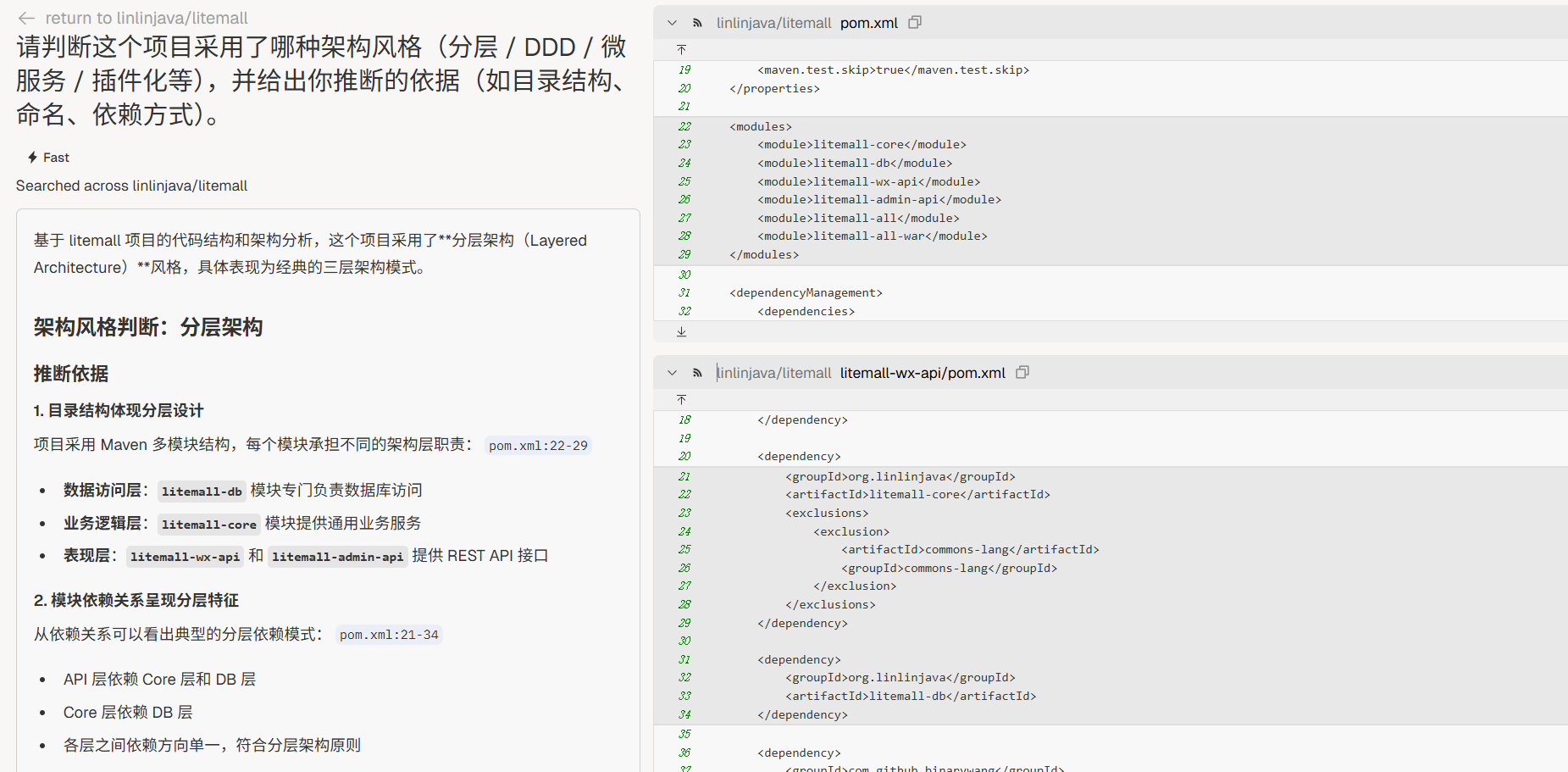
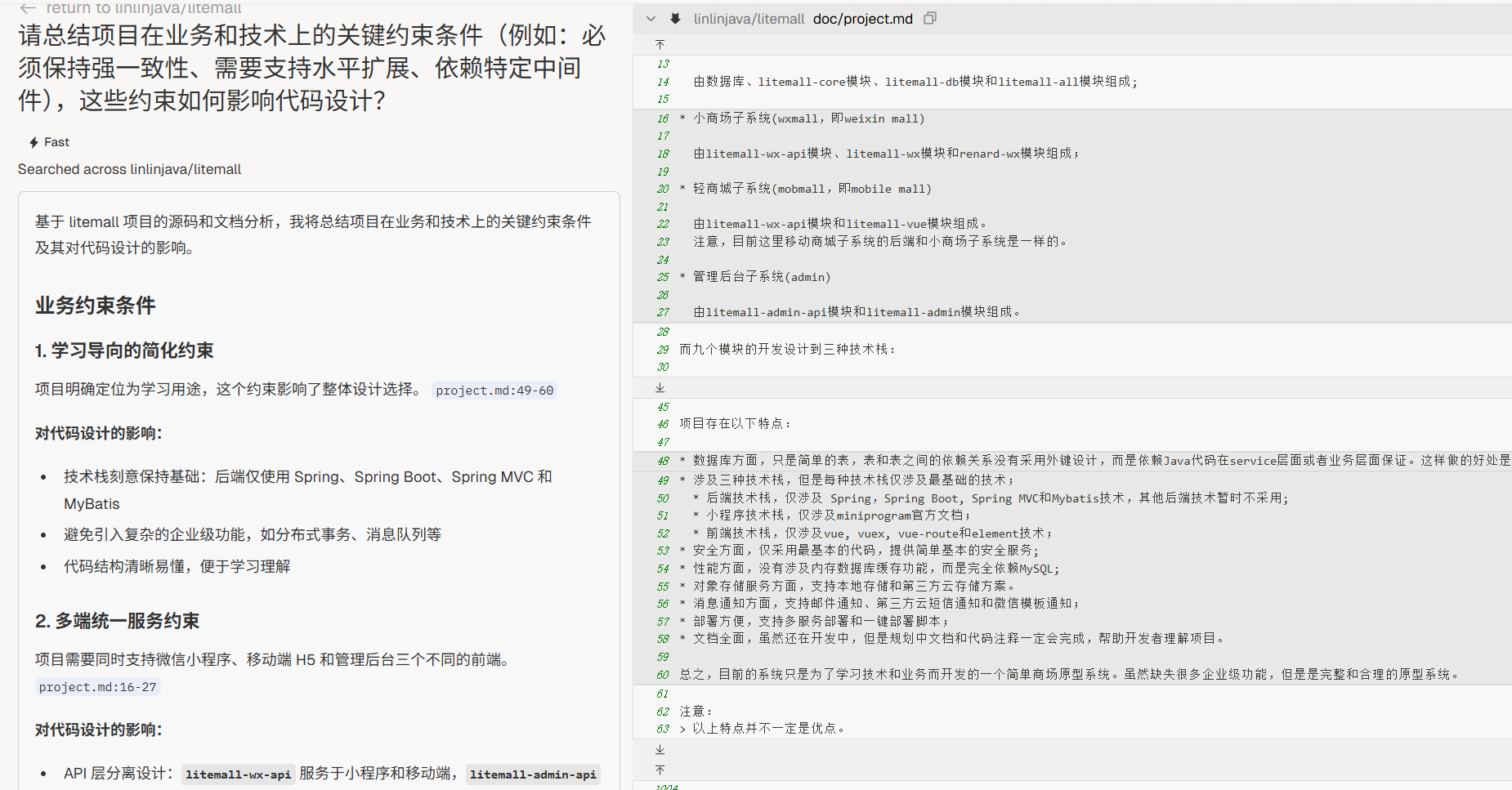
阶段 3:仓库画像(Repo Health)
要点:先对仓库做健康扫描
思考问题
- 代码规模、语言构成、目录习惯?
- 最近 3 个月活跃度如何?
- 分支策略 / License / 贡献指南?
AI 提问模板
代码全貌
“请统计这个仓库的代码规模(文件数、行数)、主要编程语言占比,以及常见的目录组织习惯。”
开发活跃度
“请根据最近 3 个月的提交记录,分析活跃度:提交频率、活跃贡献者数量、是否存在核心开发者。”
演进趋势
“请帮我识别最近 3 个月内改动最频繁的 3 个目录/模块,并推测这些改动背后的原因(Bug 修复?新特性?重构?)。”
协作规范
“请检查仓库中是否存在 CONTRIBUTING.md、CODE_OF_CONDUCT.md、分支策略说明等文件,如果有,请总结其主要要求。”
合规性扫描
“请识别仓库的 License 类型,以及它对二次开发或商用的限制条件,并简要说明影响。”
案例
阶段 4:环境与运行(Make It Run)
要点:跑起来比什么都重要
思考问题
- 最小可运行步骤是什么?
- 常见启动失败点在哪?
- 有哪些一键脚本?
AI 提问模板
最小运行路径
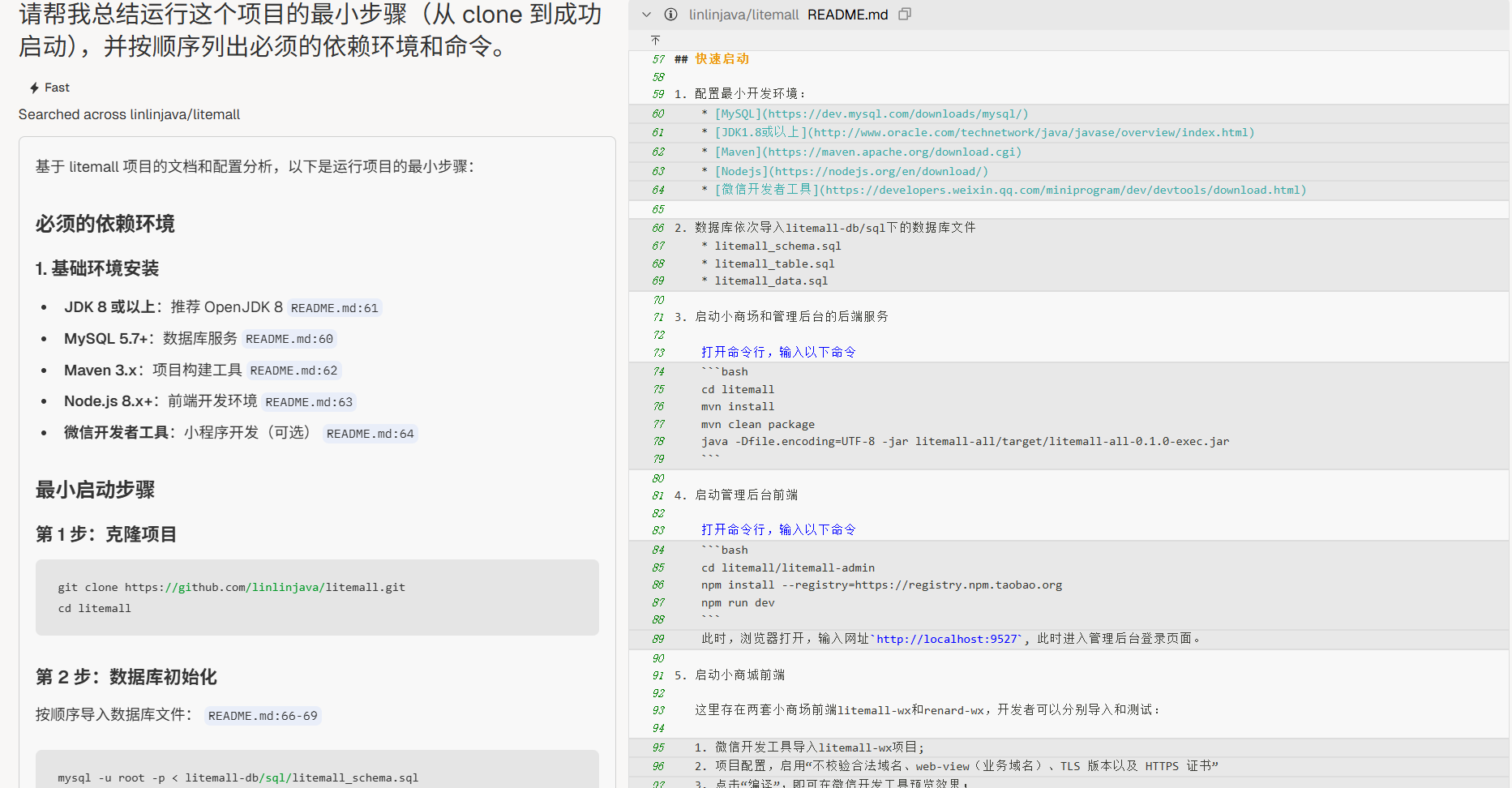
“请帮我总结运行这个项目的最小步骤(从 clone 到成功启动),并按顺序列出必须的依赖环境和命令。”
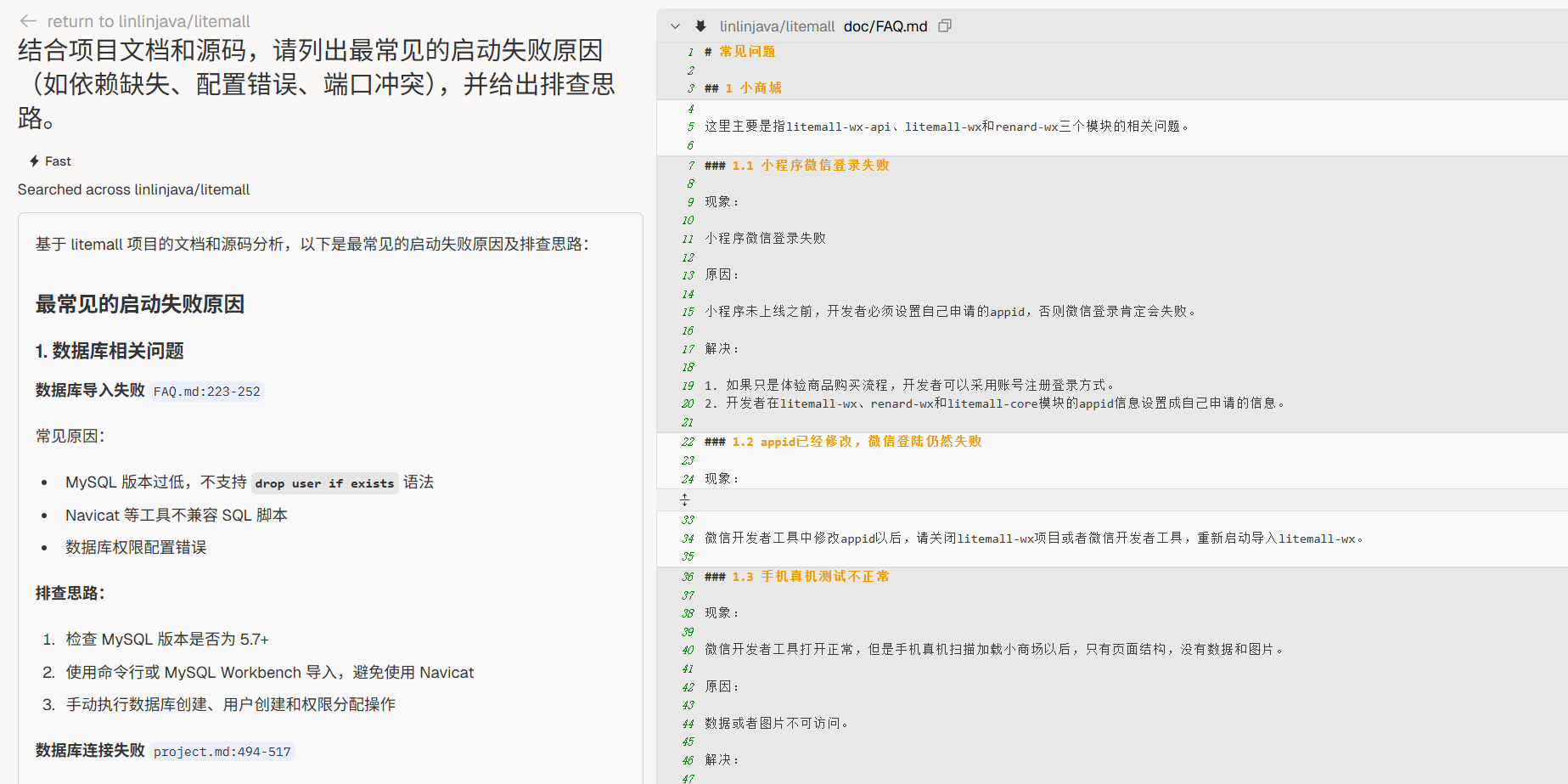
启动风险点
“结合项目文档和源码,请列出最常见的启动失败原因(如依赖缺失、配置错误、端口冲突),并给出排查思路。”
一键脚本分析
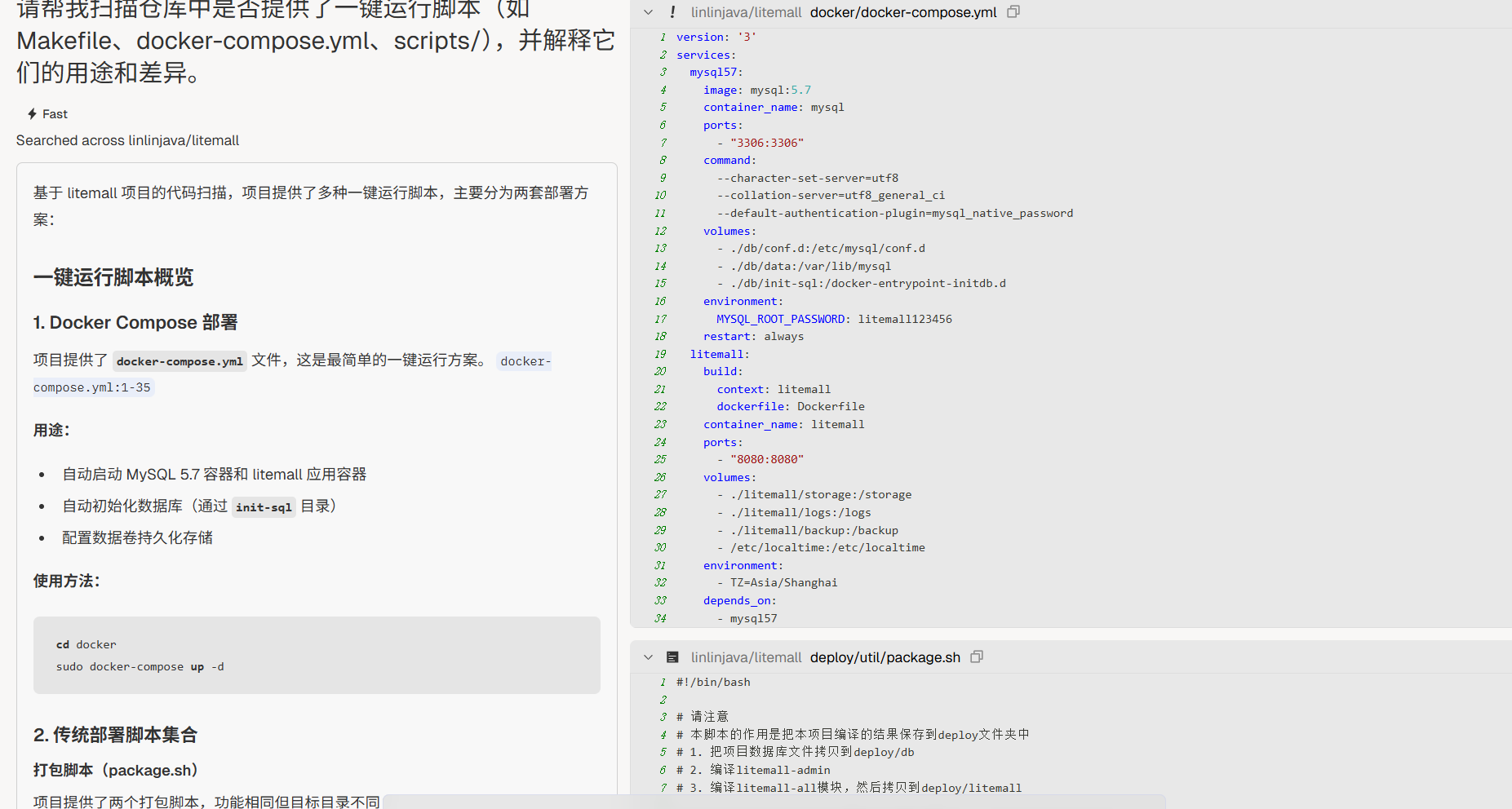
“请帮我扫描仓库中是否提供了一键运行脚本(如
Makefile、docker-compose.yml、scripts/),并解释它们的用途和差异。”环境依赖梳理
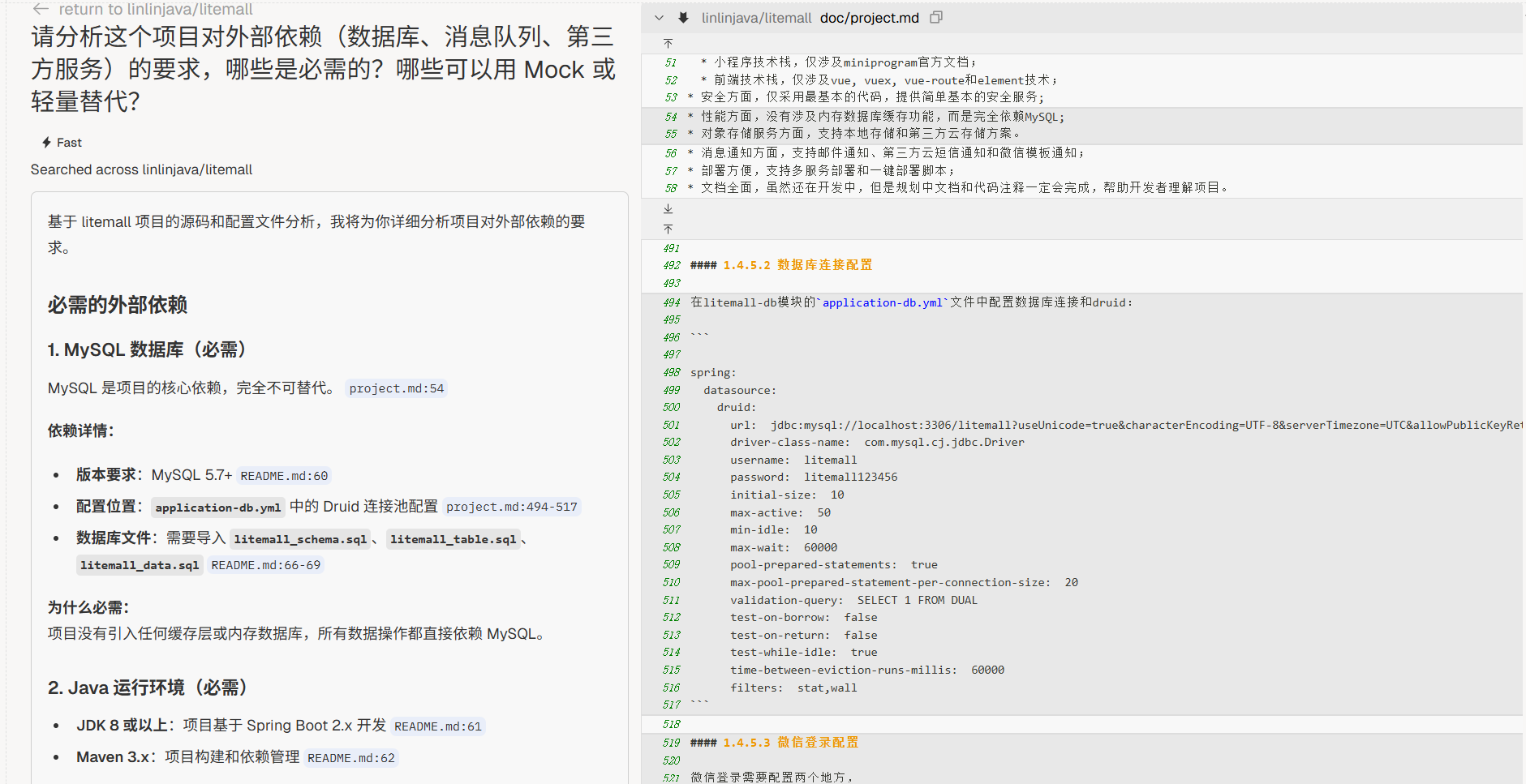
“请分析这个项目对外部依赖(数据库、消息队列、第三方服务)的要求,哪些是必需的?哪些可以用 Mock 或轻量替代?”
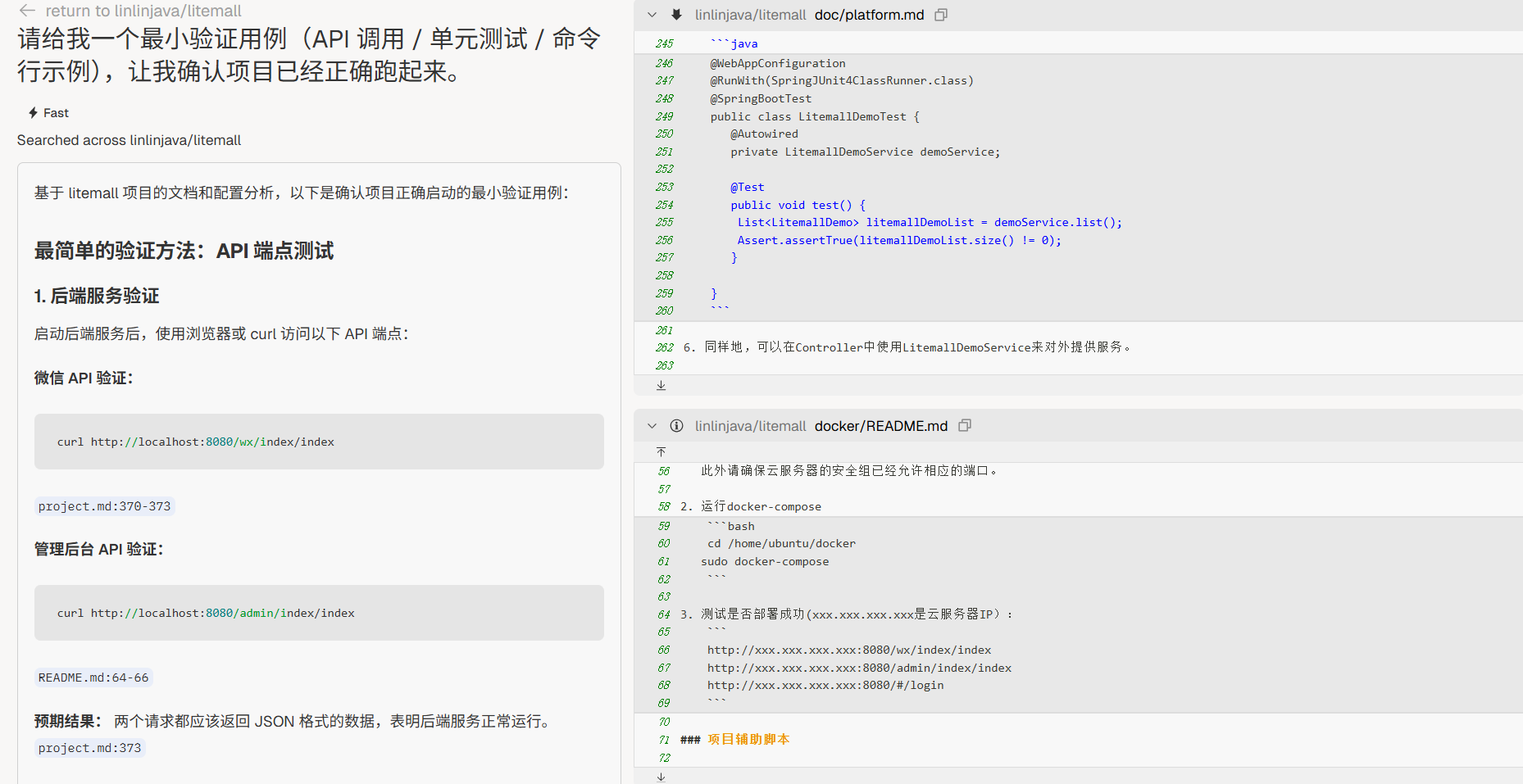
运行验证
“请给我一个最小验证用例(API 调用 / 单元测试 / 命令行示例),让我确认项目已经正确跑起来。”
案例
阶段 5:结构鸟瞰(Map the Terrain)
要点:建立项目地图
思考问题
- 项目的入口点在哪里?
- 模块边界如何?依赖关系走向?
- 哪些模块是稳定内核,哪些是易变外围?
AI 提问模板
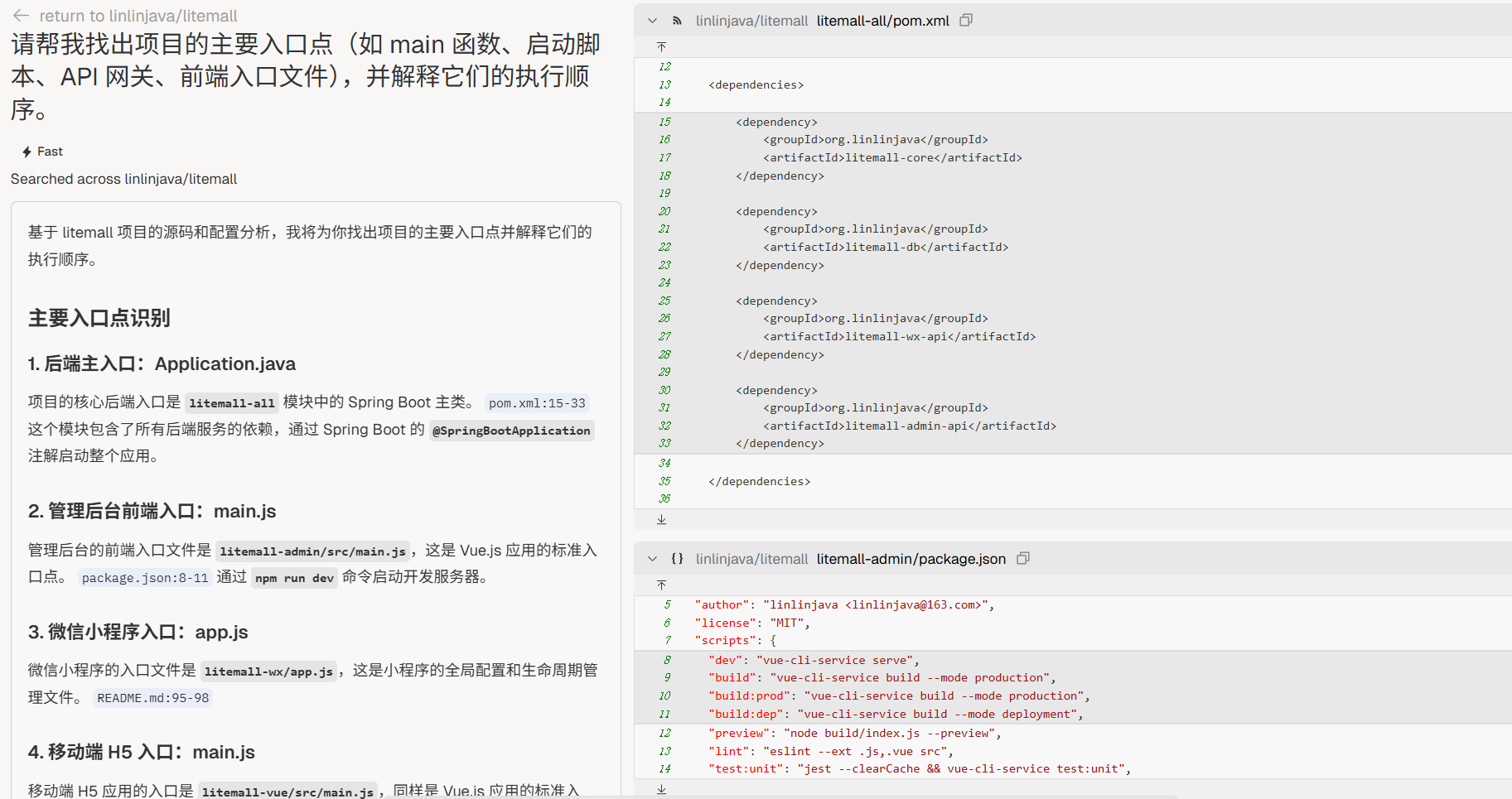
入口识别
“请帮我找出项目的主要入口点(如
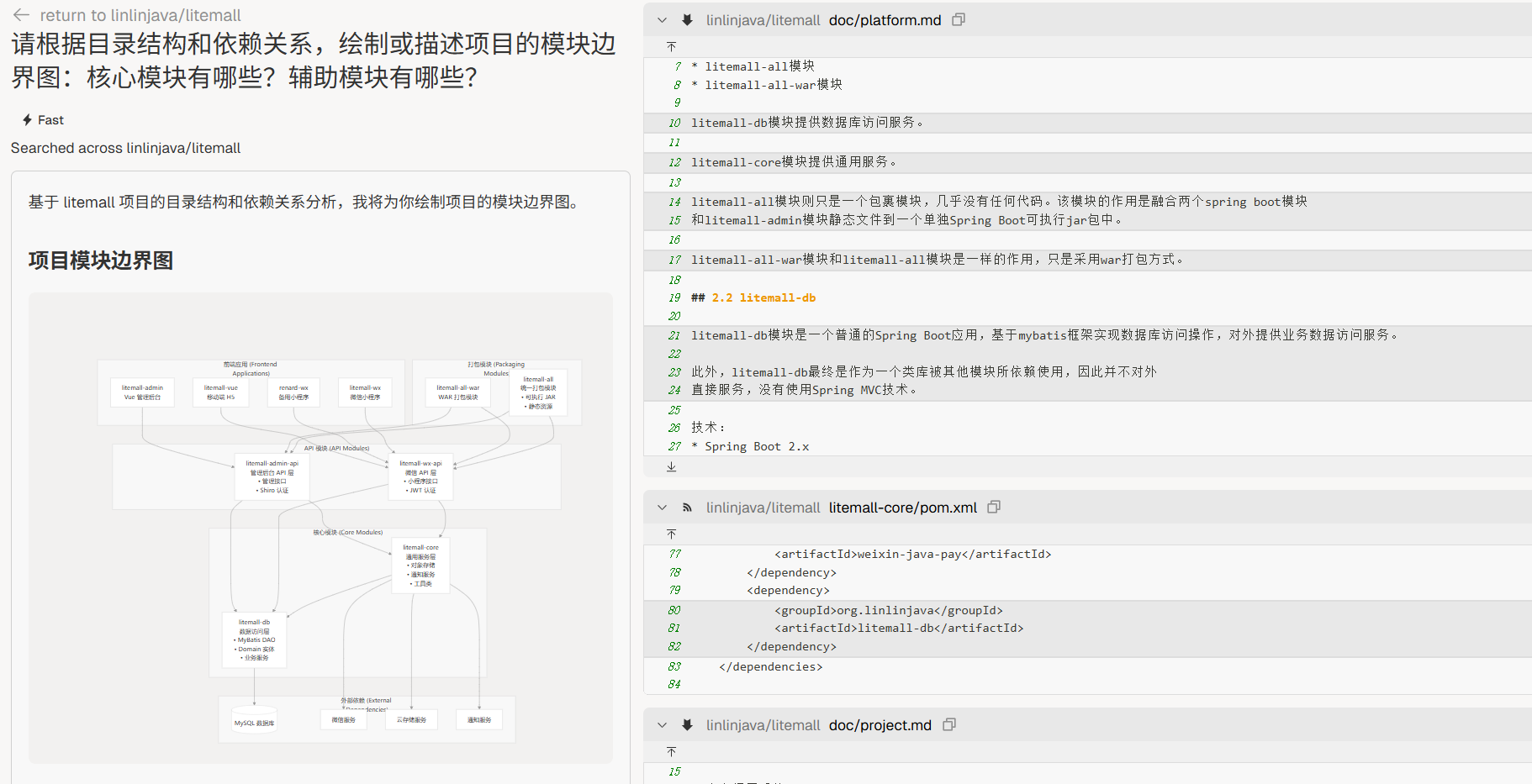
main函数、启动脚本、API 网关、前端入口文件),并解释它们的执行顺序。”模块地图
“请根据目录结构和依赖关系,绘制或描述项目的模块边界图:核心模块有哪些?辅助模块有哪些?”
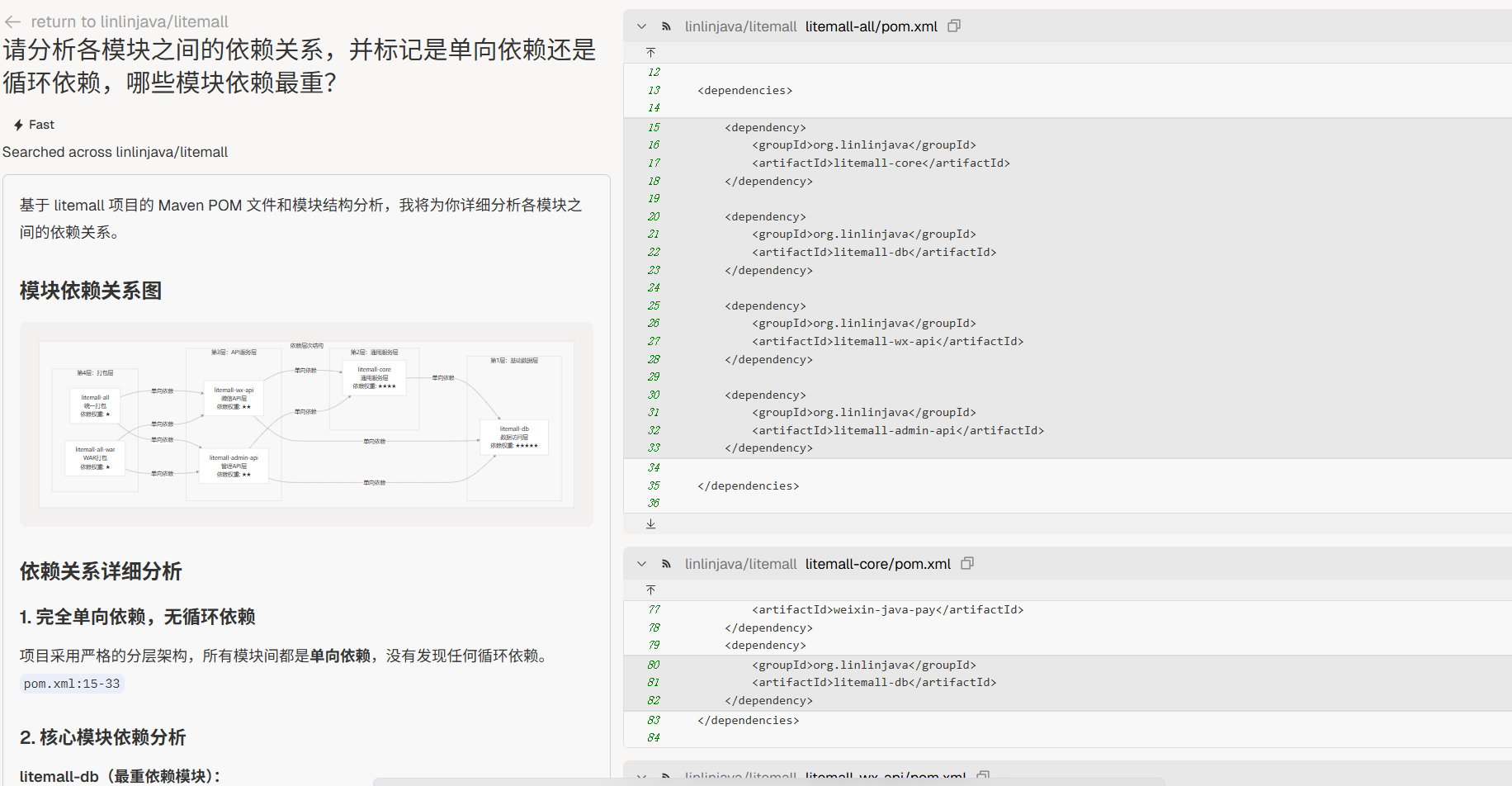
依赖走向
“请分析各模块之间的依赖关系,并标记是单向依赖还是循环依赖,哪些模块依赖最重?”
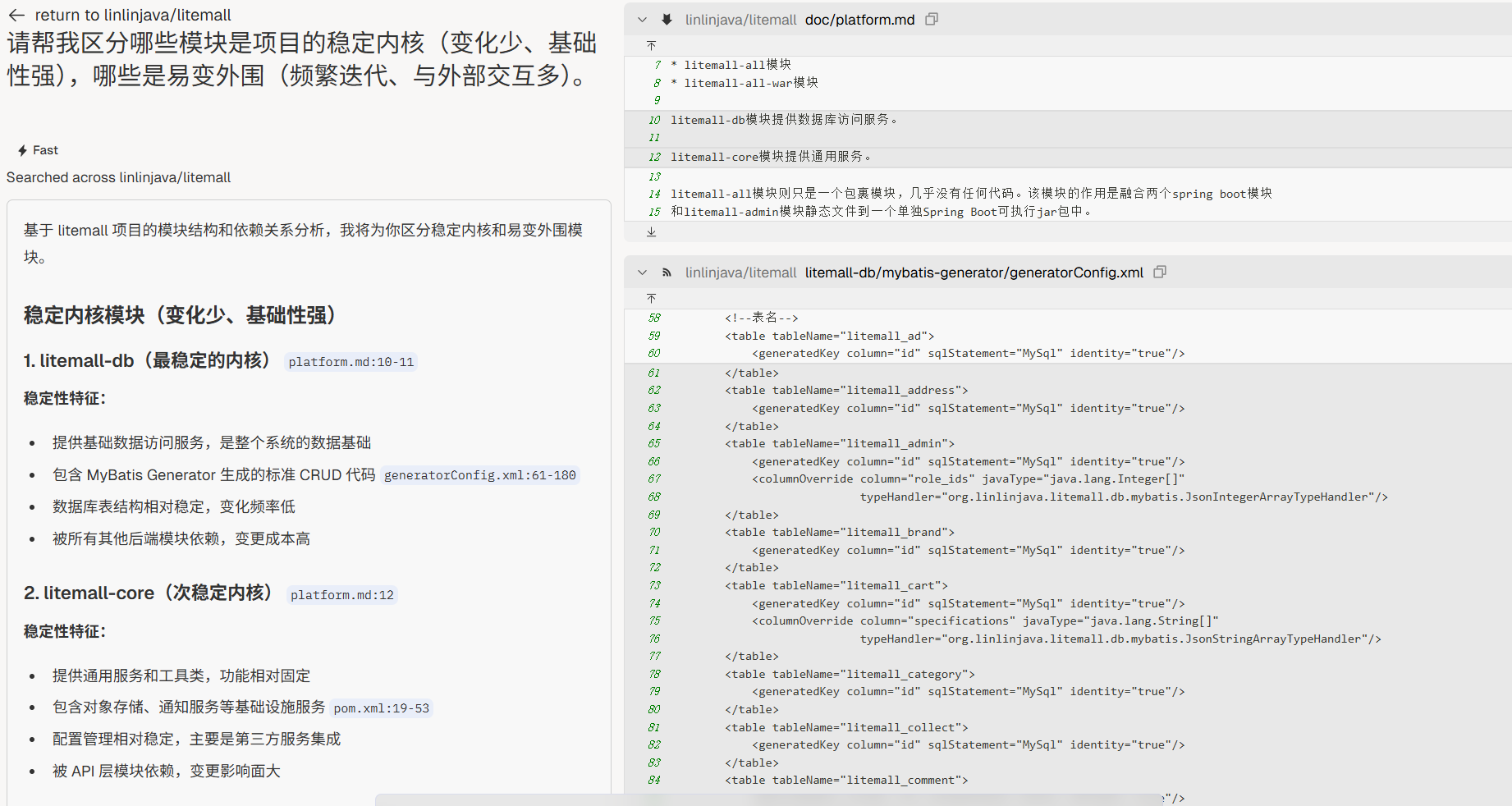
稳定 vs 易变
“请帮我区分哪些模块是项目的稳定内核(变化少、基础性强),哪些是易变外围(频繁迭代、与外部交互多)。”
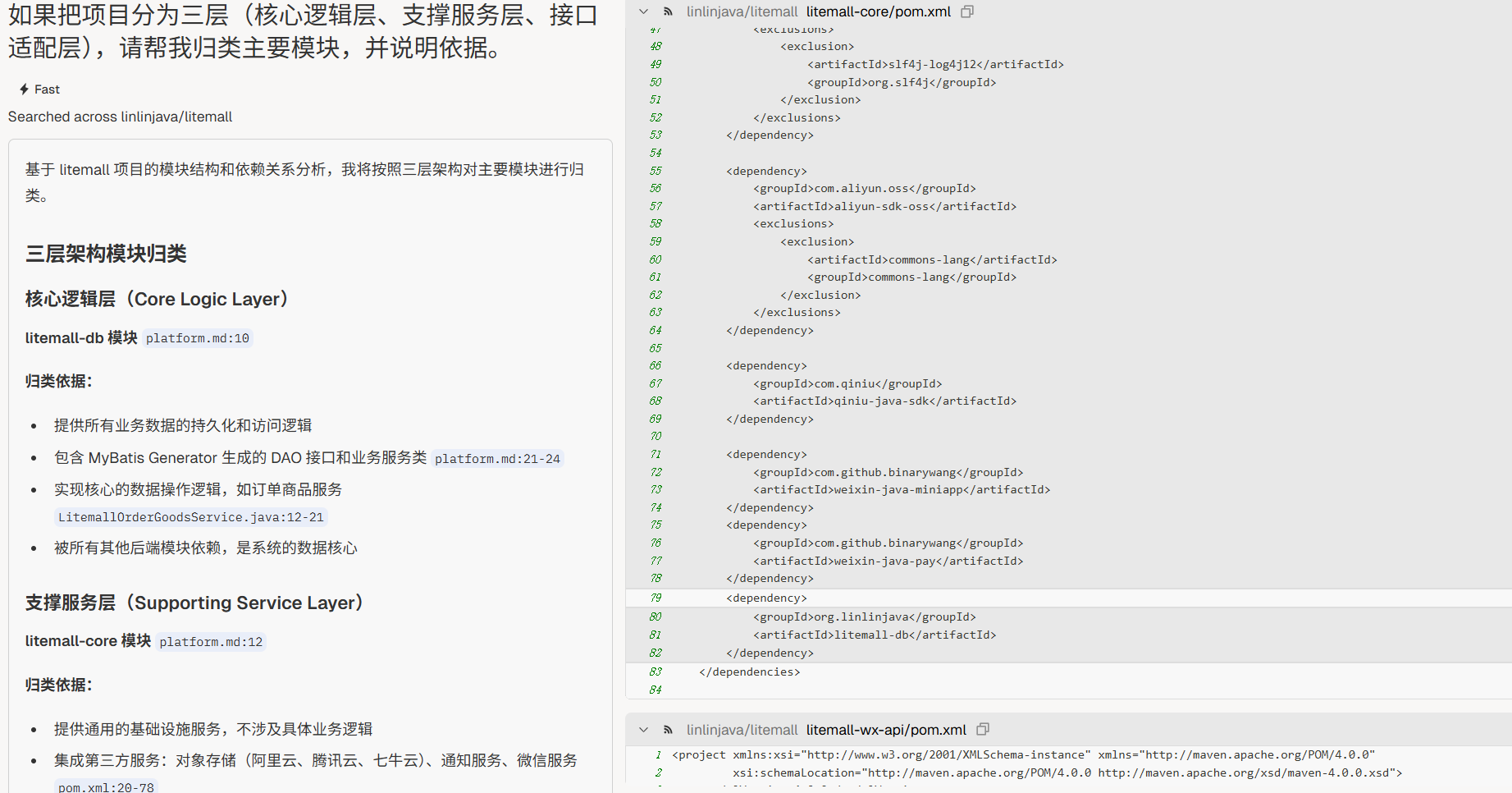
层次化视角
“如果把项目分为三层(核心逻辑层、支撑服务层、接口适配层),请帮我归类主要模块,并说明依据。”
案例
阶段 6:主线追踪(Happy Path)
要点:先走通核心用例
思考问题
- 核心用例的调用链是怎样的?
- 策略点、扩展点在哪?
- 异常处理逻辑如何?
AI 提问模板
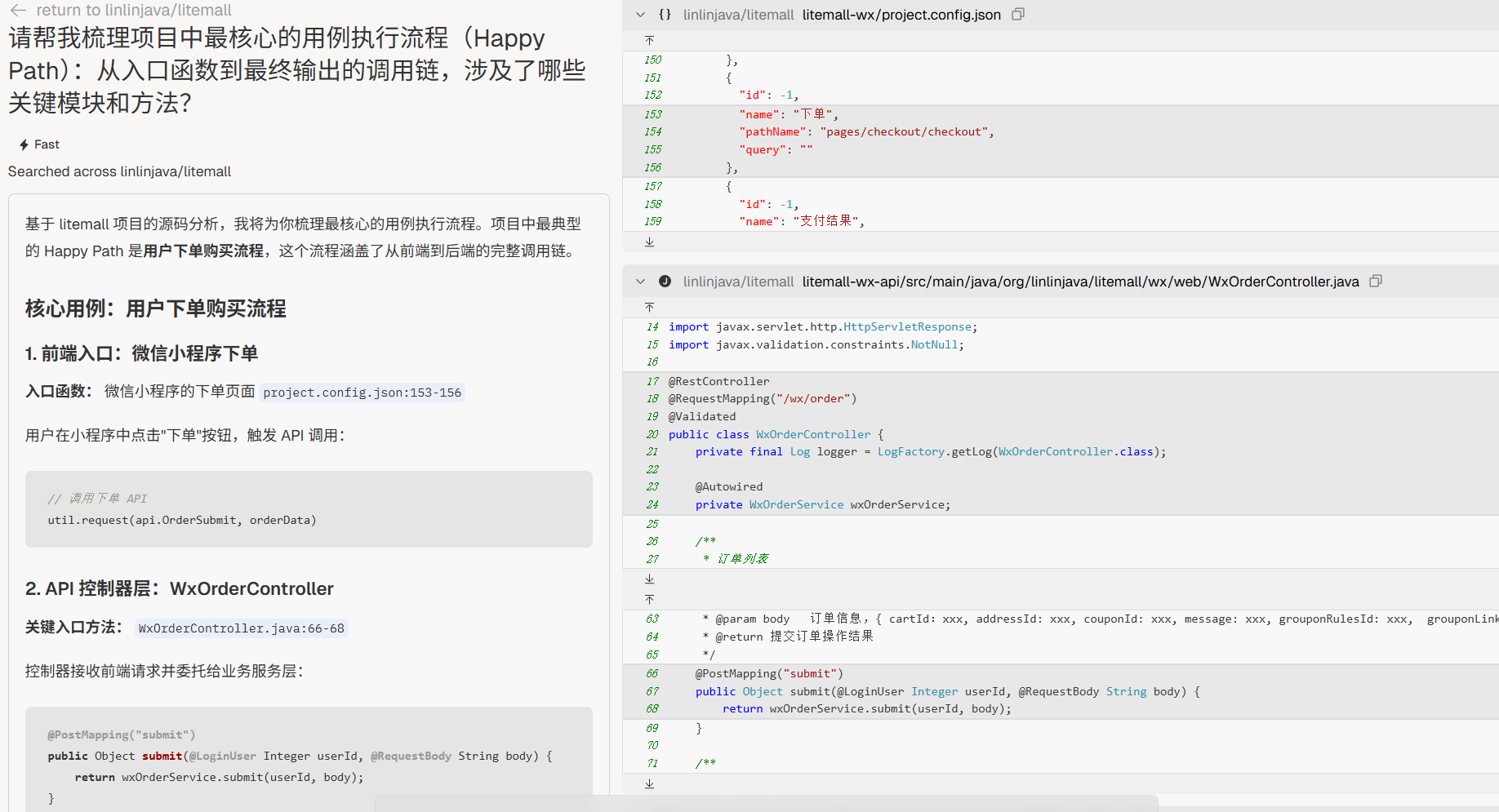
核心调用链
“请帮我梳理项目中最核心的用例执行流程(Happy Path):从入口函数到最终输出的调用链,涉及了哪些关键模块和方法?”
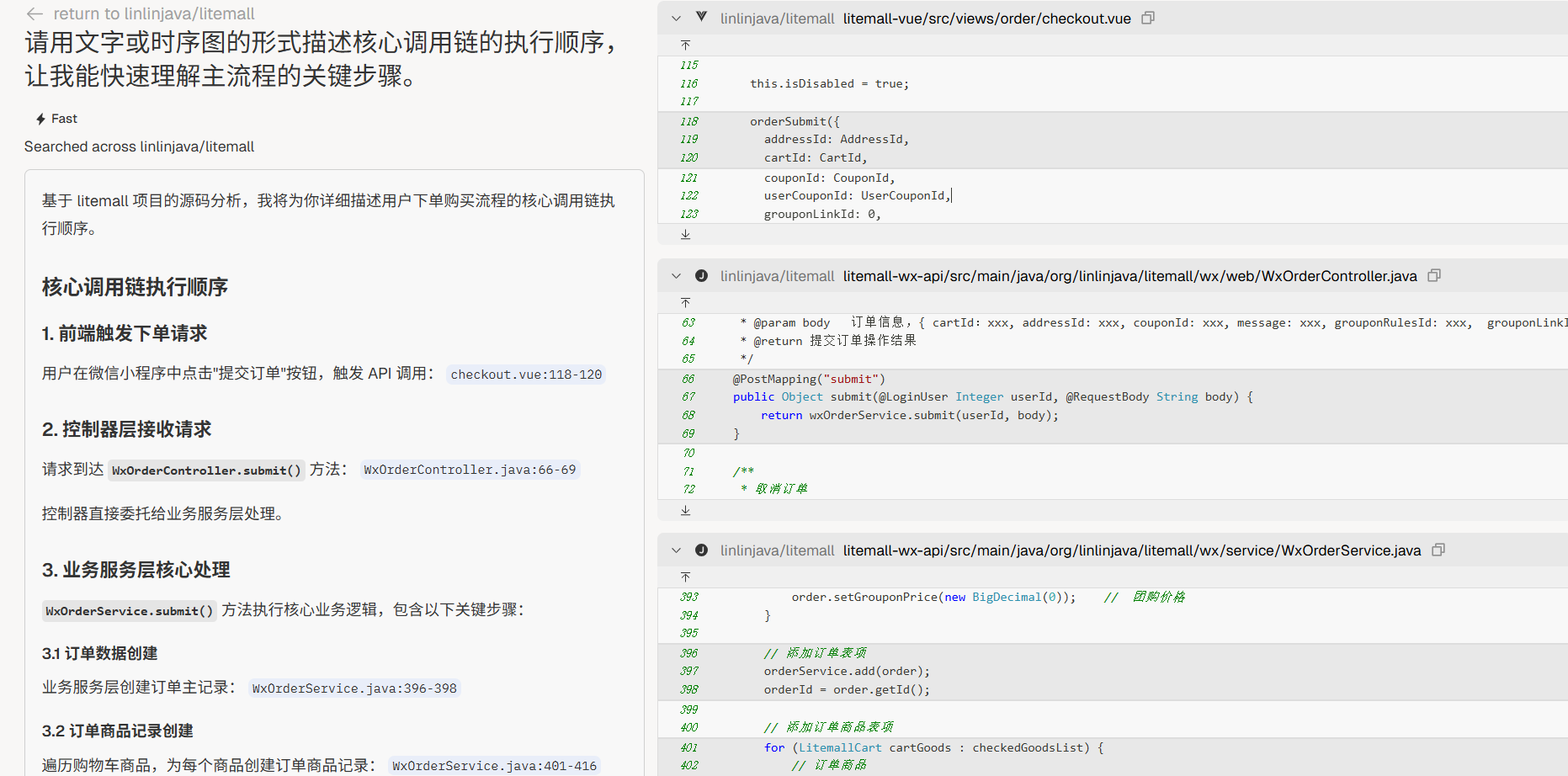
流程可视化
“请用文字或时序图的形式描述核心调用链的执行顺序,让我能快速理解主流程的关键步骤。”
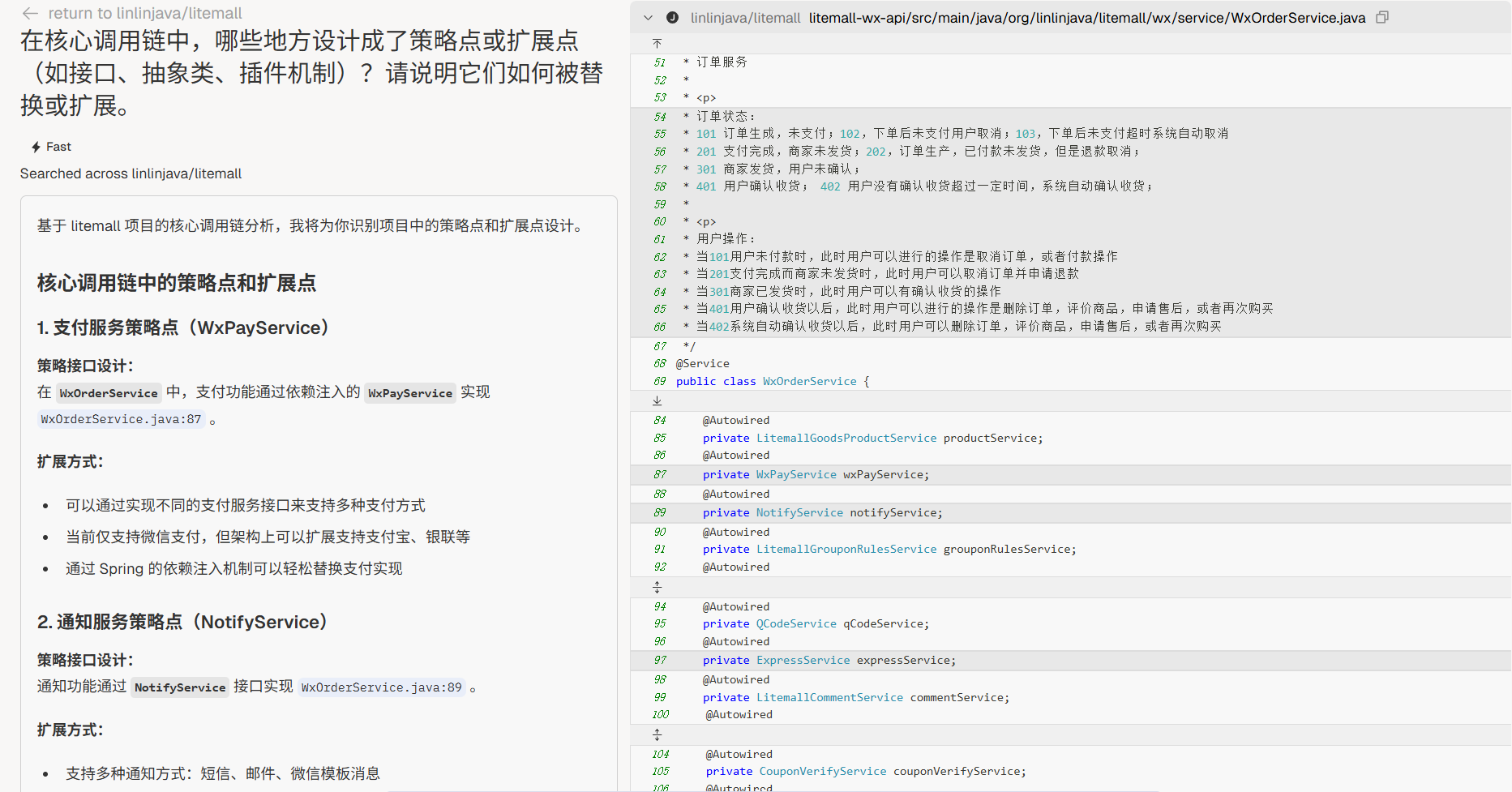
策略/扩展点
“在核心调用链中,哪些地方设计成了策略点或扩展点(如接口、抽象类、插件机制)?请说明它们如何被替换或扩展。”
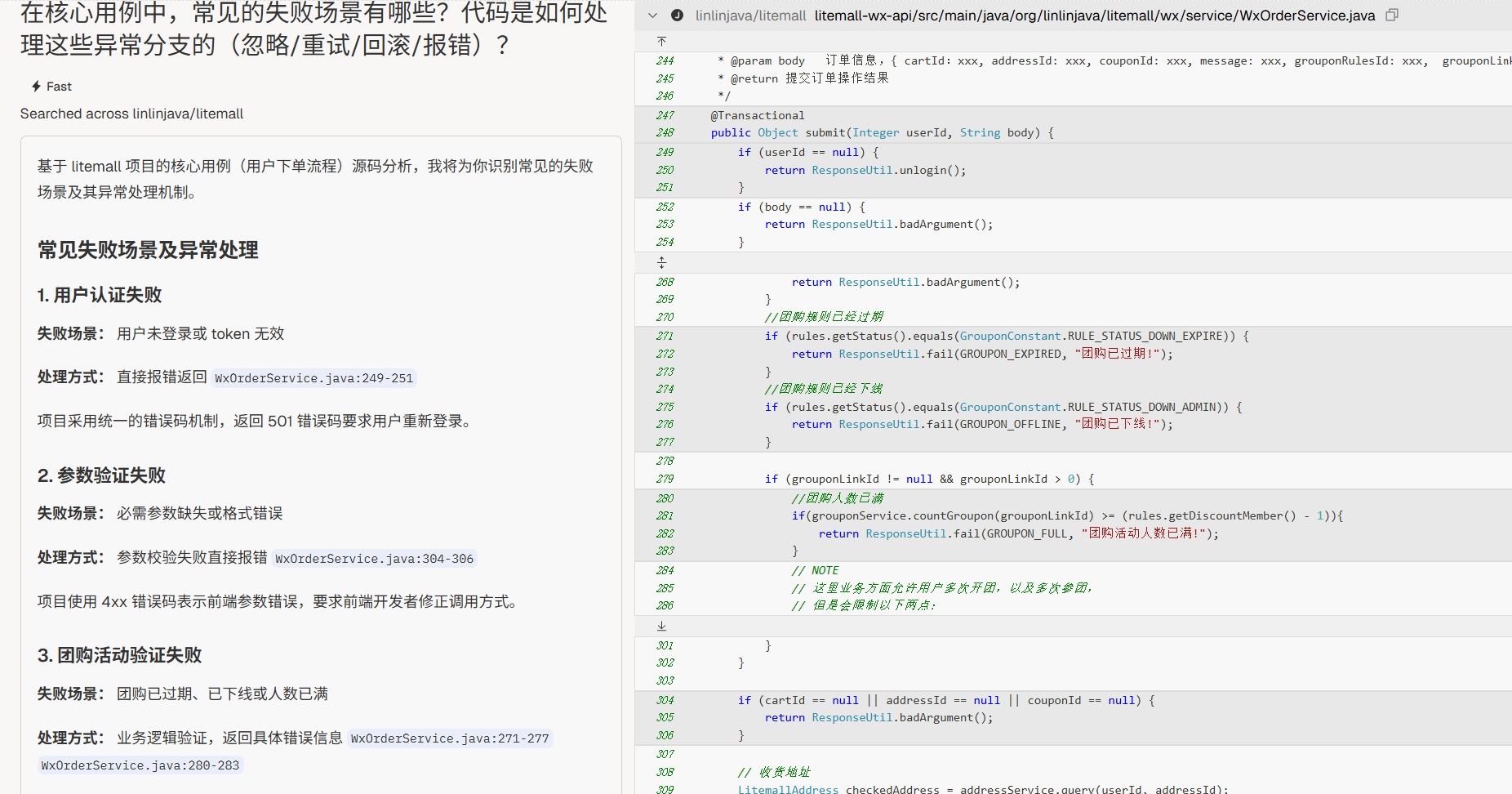
异常与分支处理
“在核心用例中,常见的失败场景有哪些?代码是如何处理这些异常分支的(忽略/重试/回滚/报错)?”
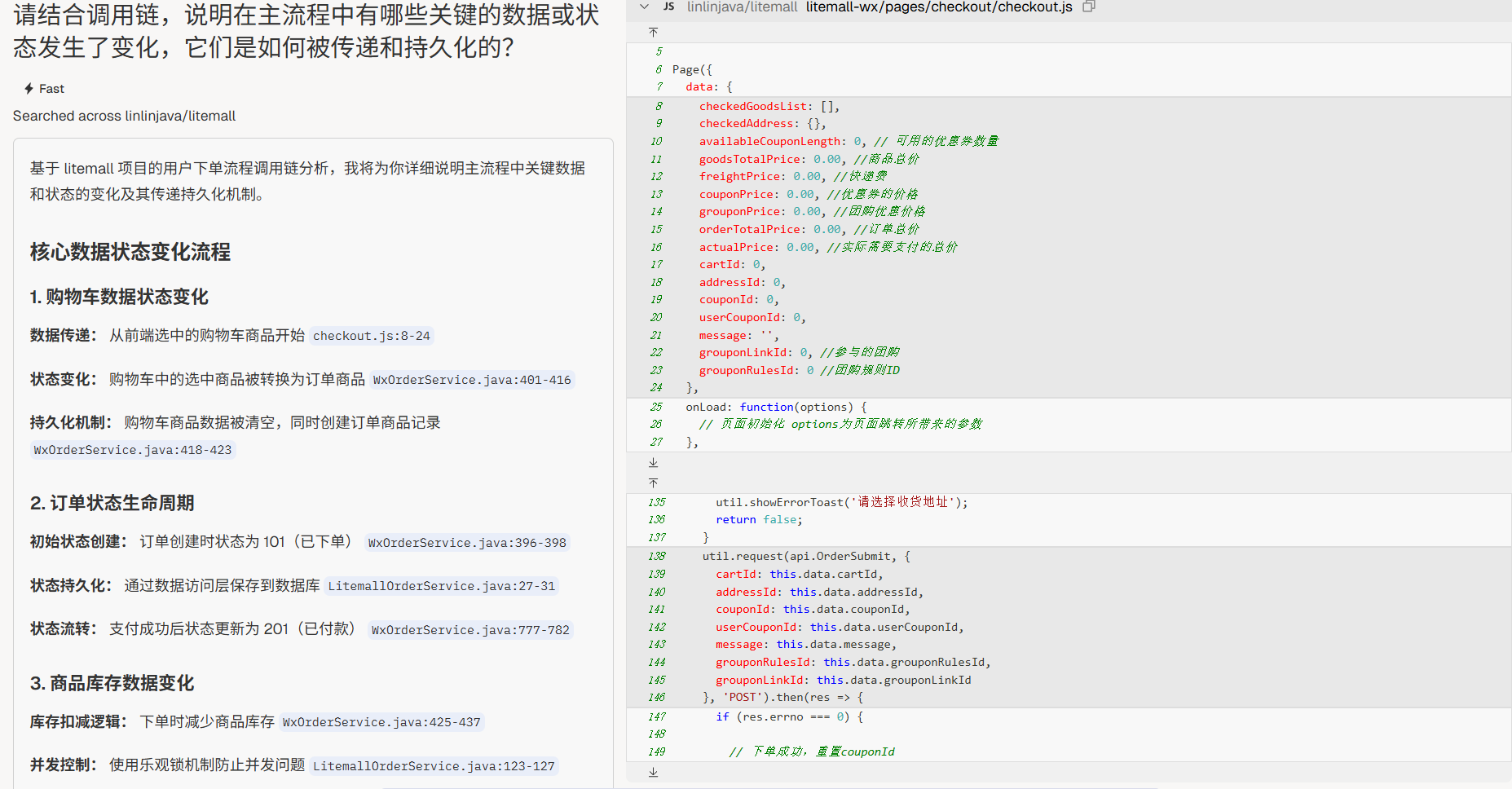
关键状态变化
“请结合调用链,说明在主流程中有哪些关键的数据或状态发生了变化,它们是如何被传递和持久化的?”
案例
阶段 7:数据与状态(Model & Consistency)
要点:理解数据和不变量
思考问题
- 核心数据结构和状态机?
- 配置 / 特性开关如何影响行为?
- 一致性和幂等如何保证?
AI 提问模板
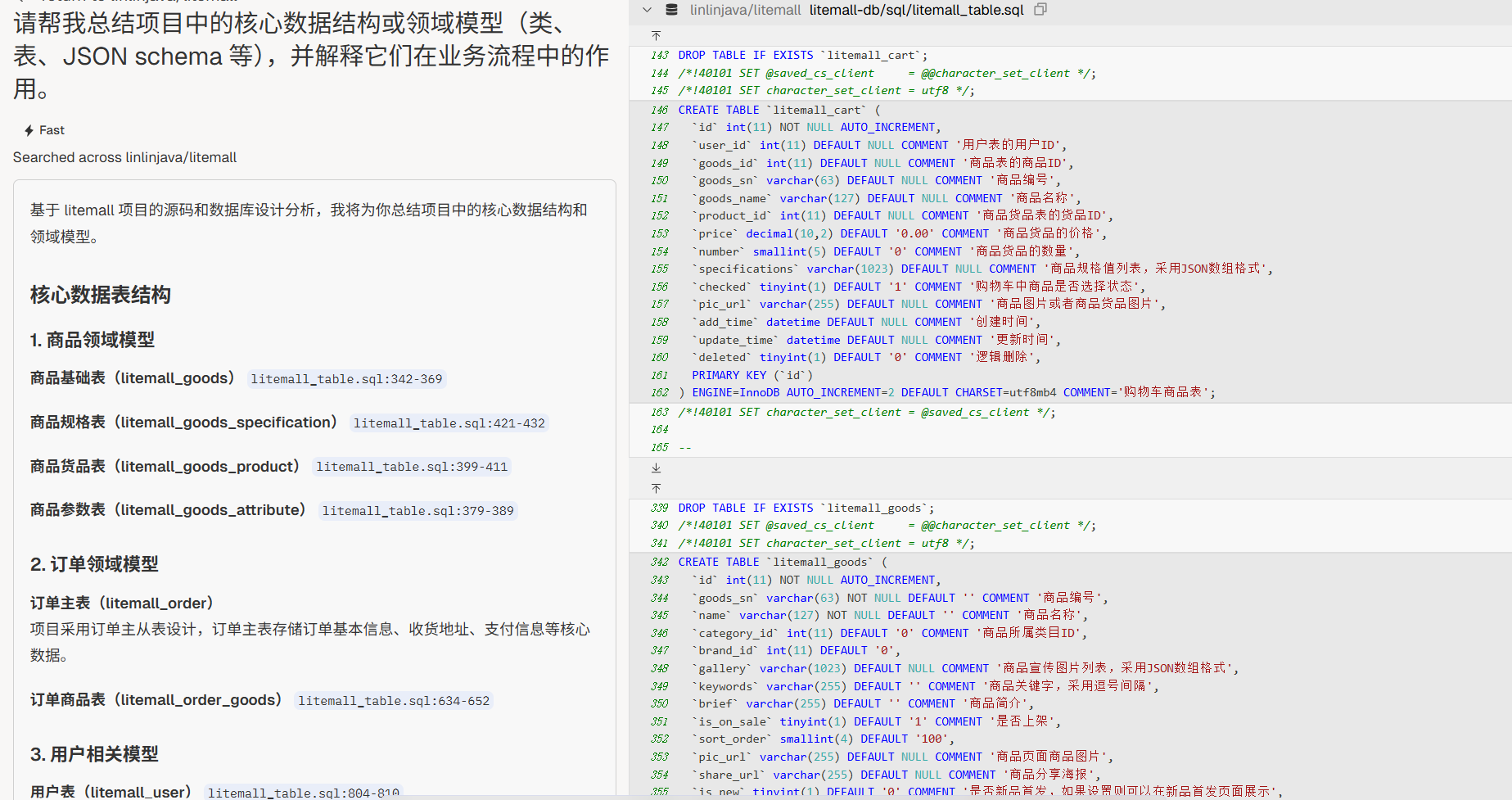
核心数据结构
“请帮我总结项目中的核心数据结构或领域模型(类、表、JSON schema 等),并解释它们在业务流程中的作用。”
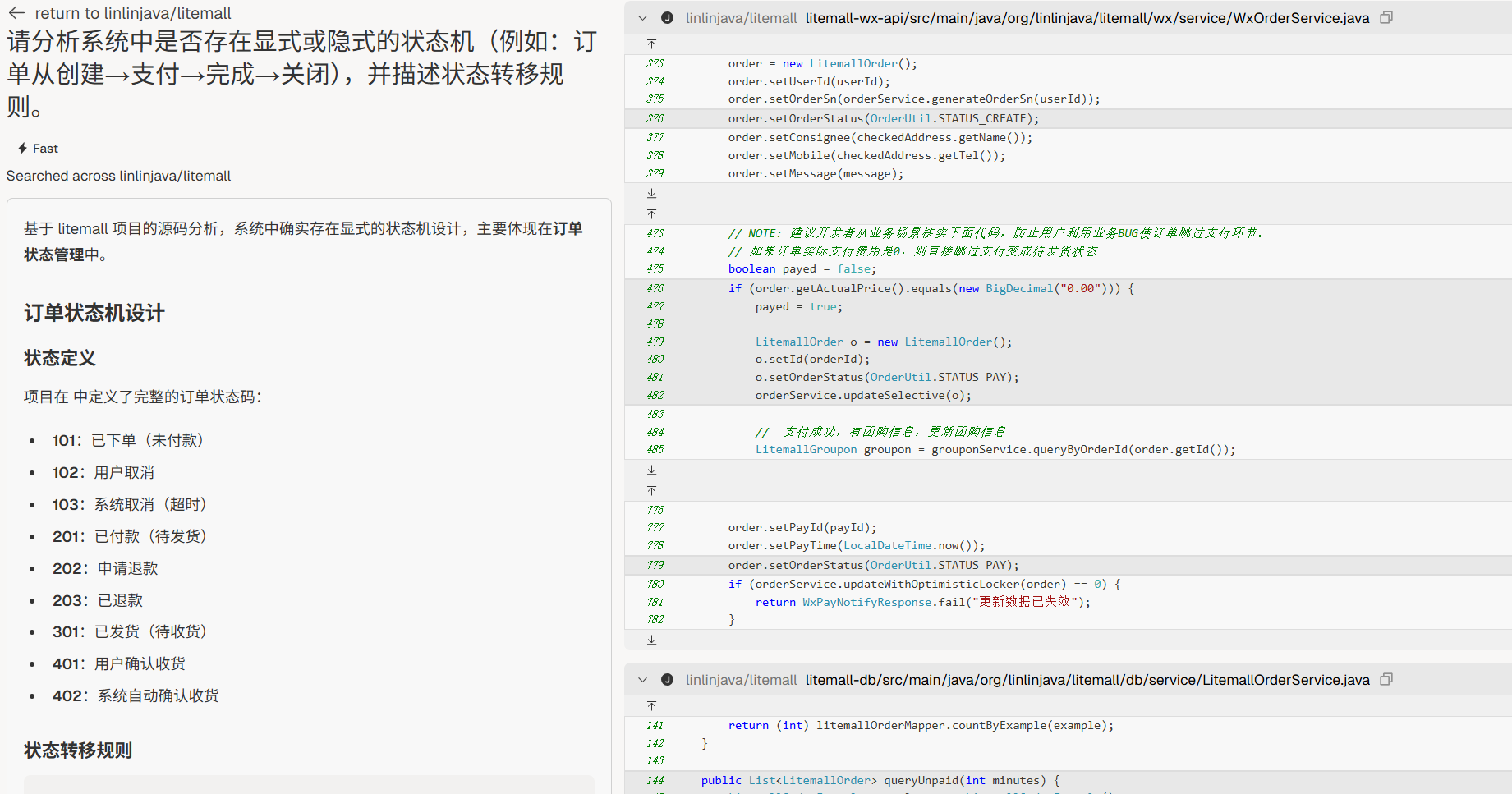
状态机建模
“请分析系统中是否存在显式或隐式的状态机(例如:订单从创建→支付→完成→关闭),并描述状态转移规则。”
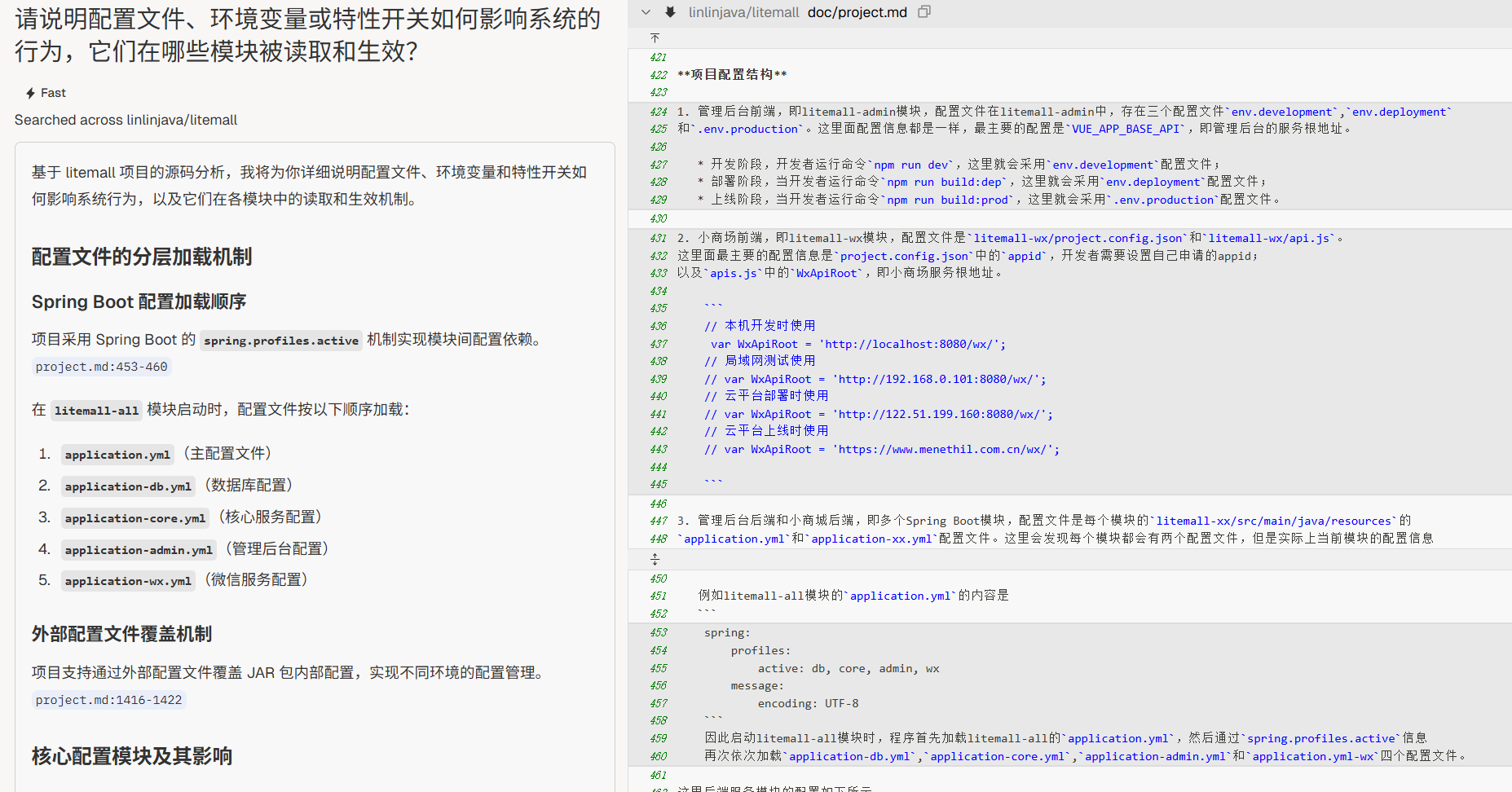
配置与特性开关
“请说明配置文件、环境变量或特性开关如何影响系统的行为,它们在哪些模块被读取和生效?”
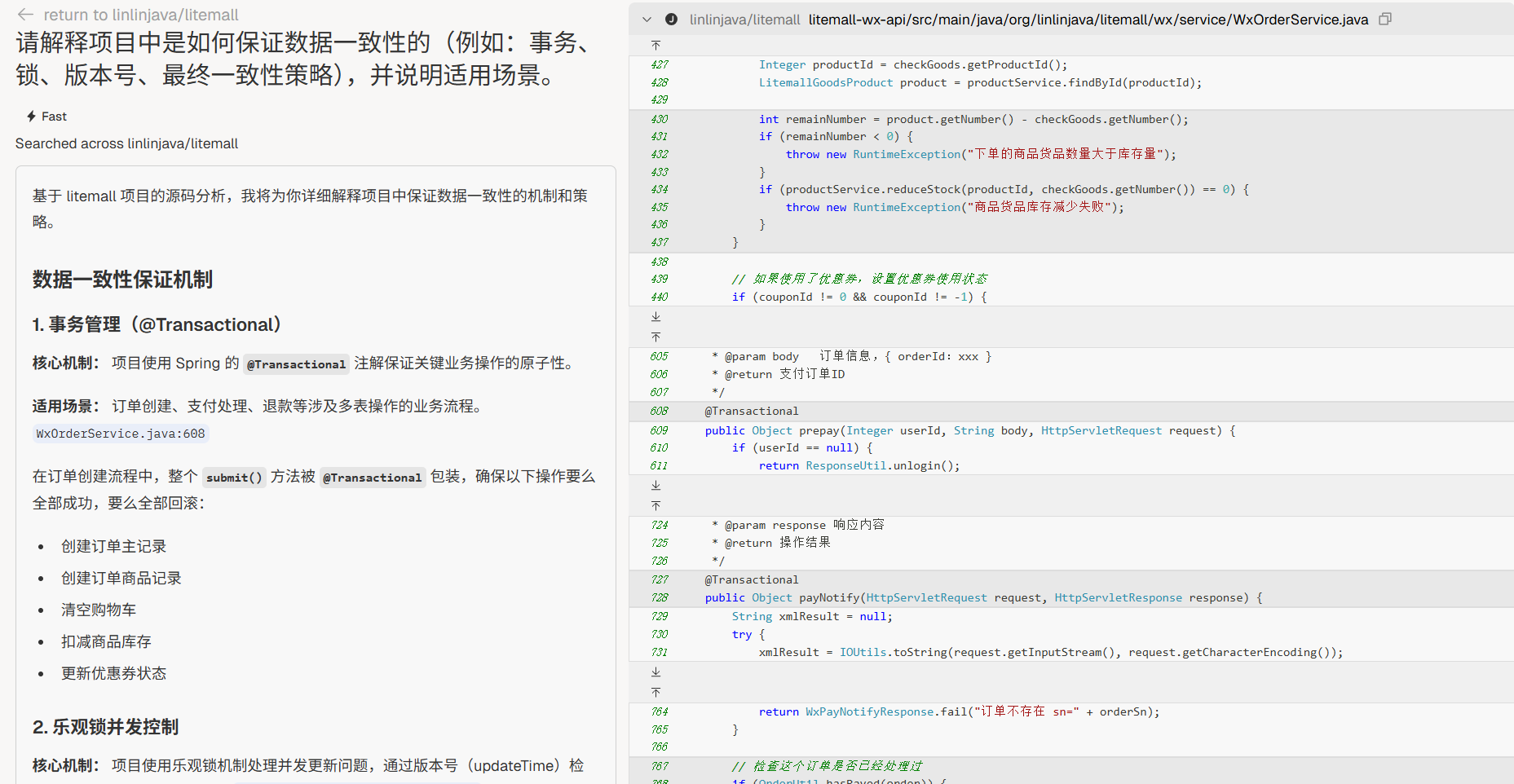
一致性机制
“请解释项目中是如何保证数据一致性的(例如:事务、锁、版本号、最终一致性策略),并说明适用场景。”
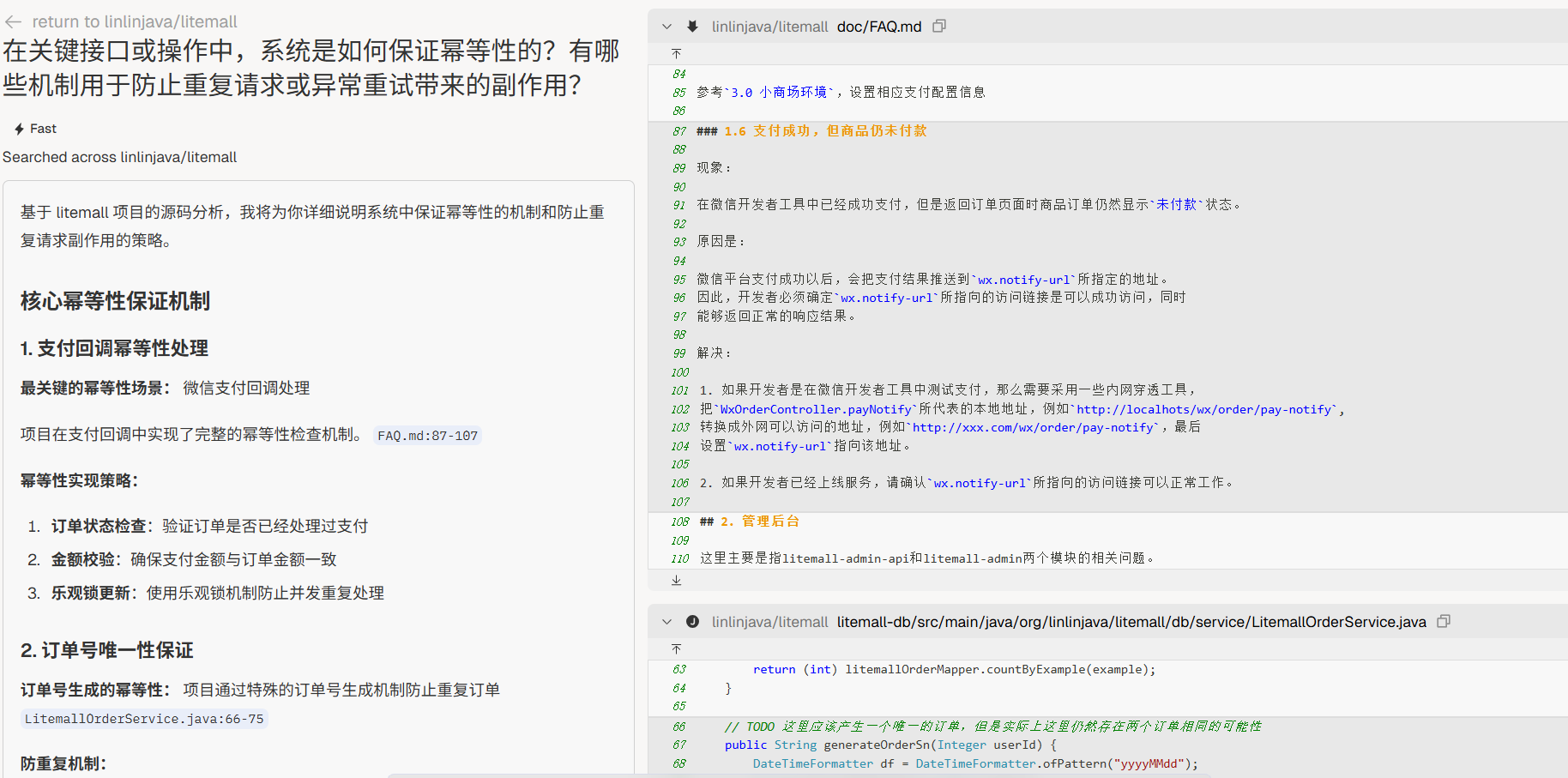
幂等与容错
“在关键接口或操作中,系统是如何保证幂等性的?有哪些机制用于防止重复请求或异常重试带来的副作用?”
案例
阶段 8:历史演化(Why This Code Exists)
要点:理解历史原因,避免盲猜
思考问题
- 最近关键 PR/Issue 的动机?
- 哪些奇怪实现有历史包袱?
- 哪些模块是高频变更点?
AI 提问模板
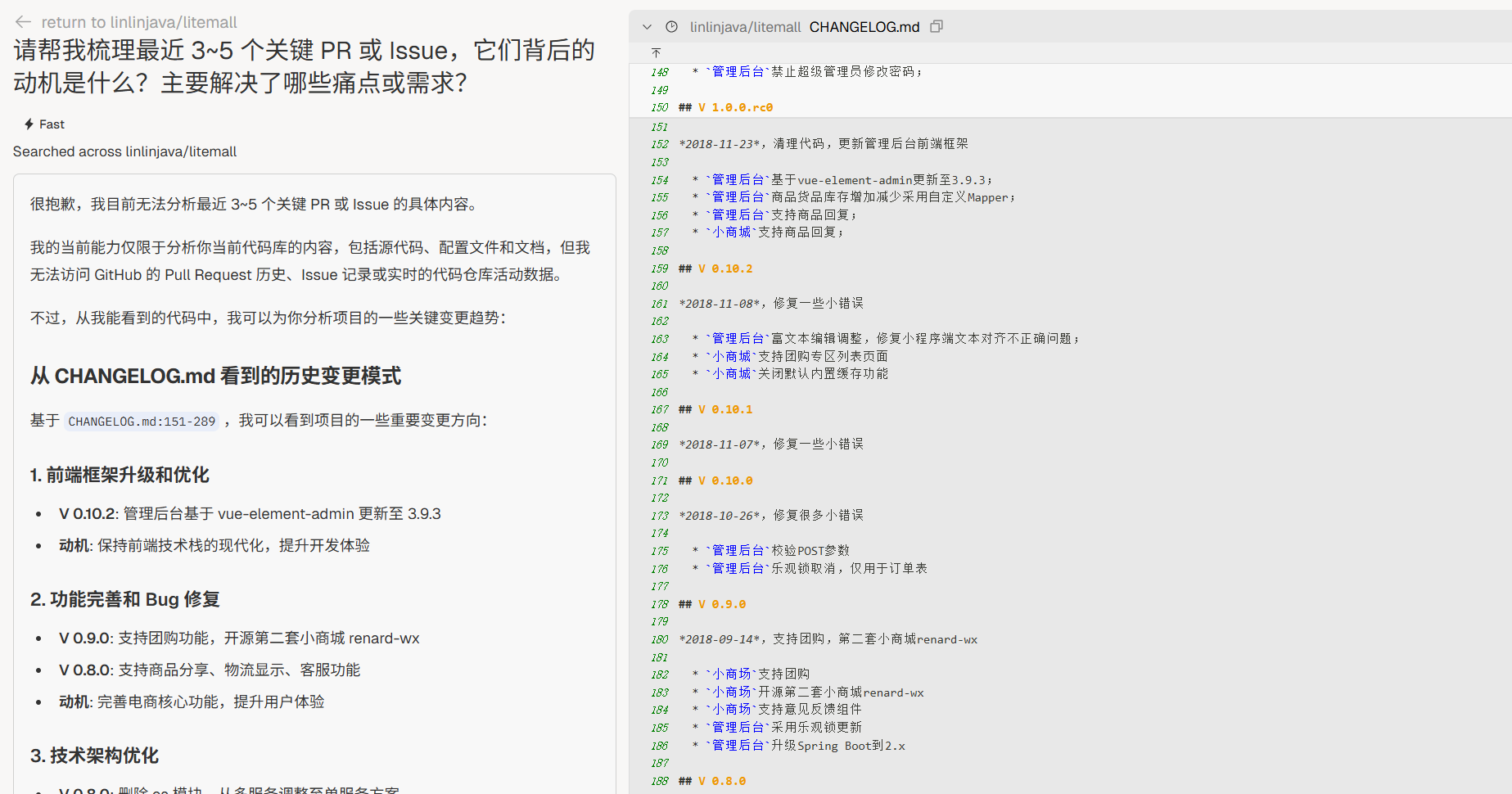
关键变更动机
“请帮我梳理最近 3~5 个关键 PR 或 Issue,它们背后的动机是什么?主要解决了哪些痛点或需求?”
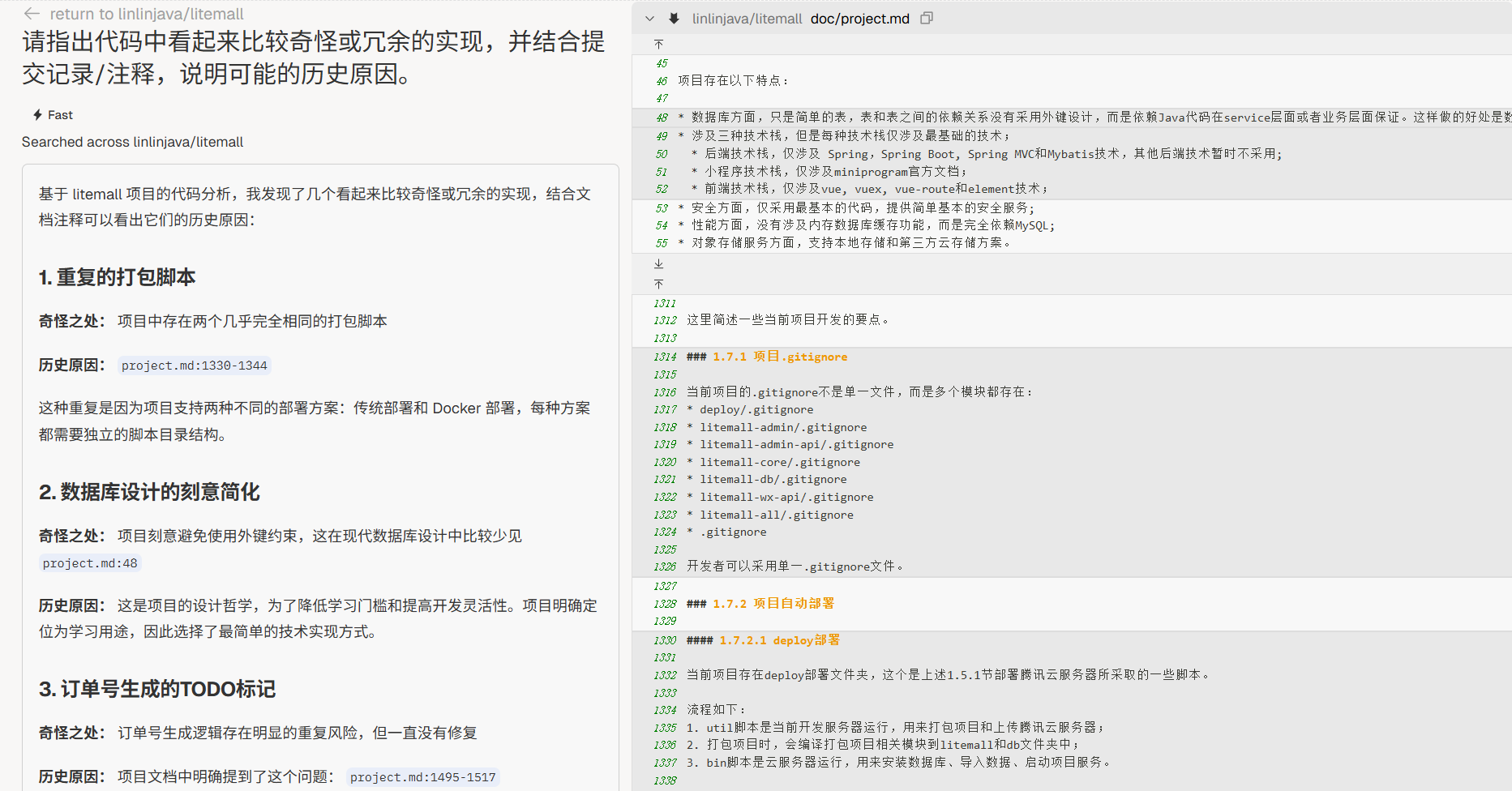
历史包袱识别
“请指出代码中看起来比较奇怪或冗余的实现,并结合提交记录/注释,说明可能的历史原因。”
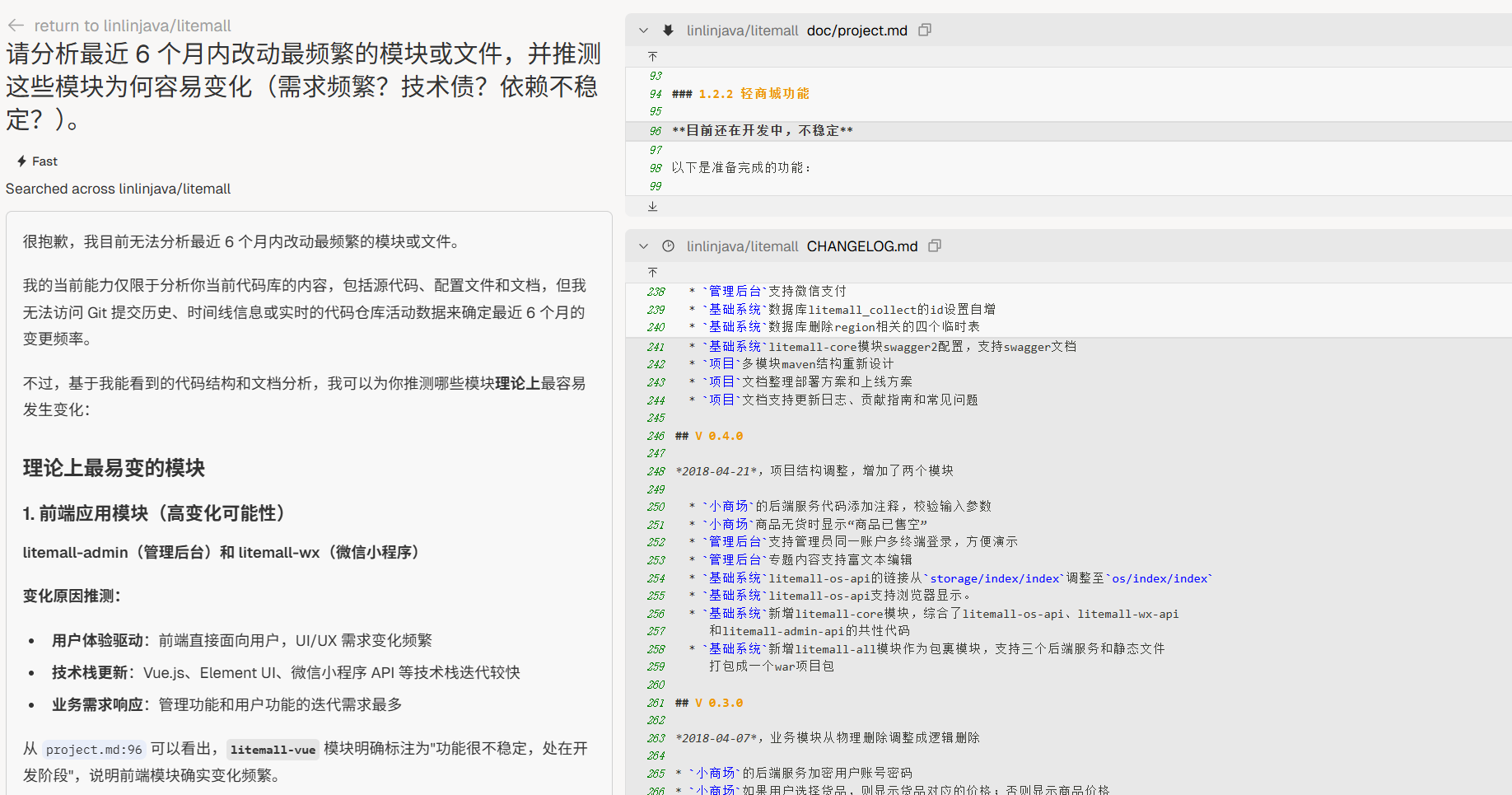
高频变更点
“请分析最近 6 个月内改动最频繁的模块或文件,并推测这些模块为何容易变化(需求频繁?技术债?依赖不稳定?)。”
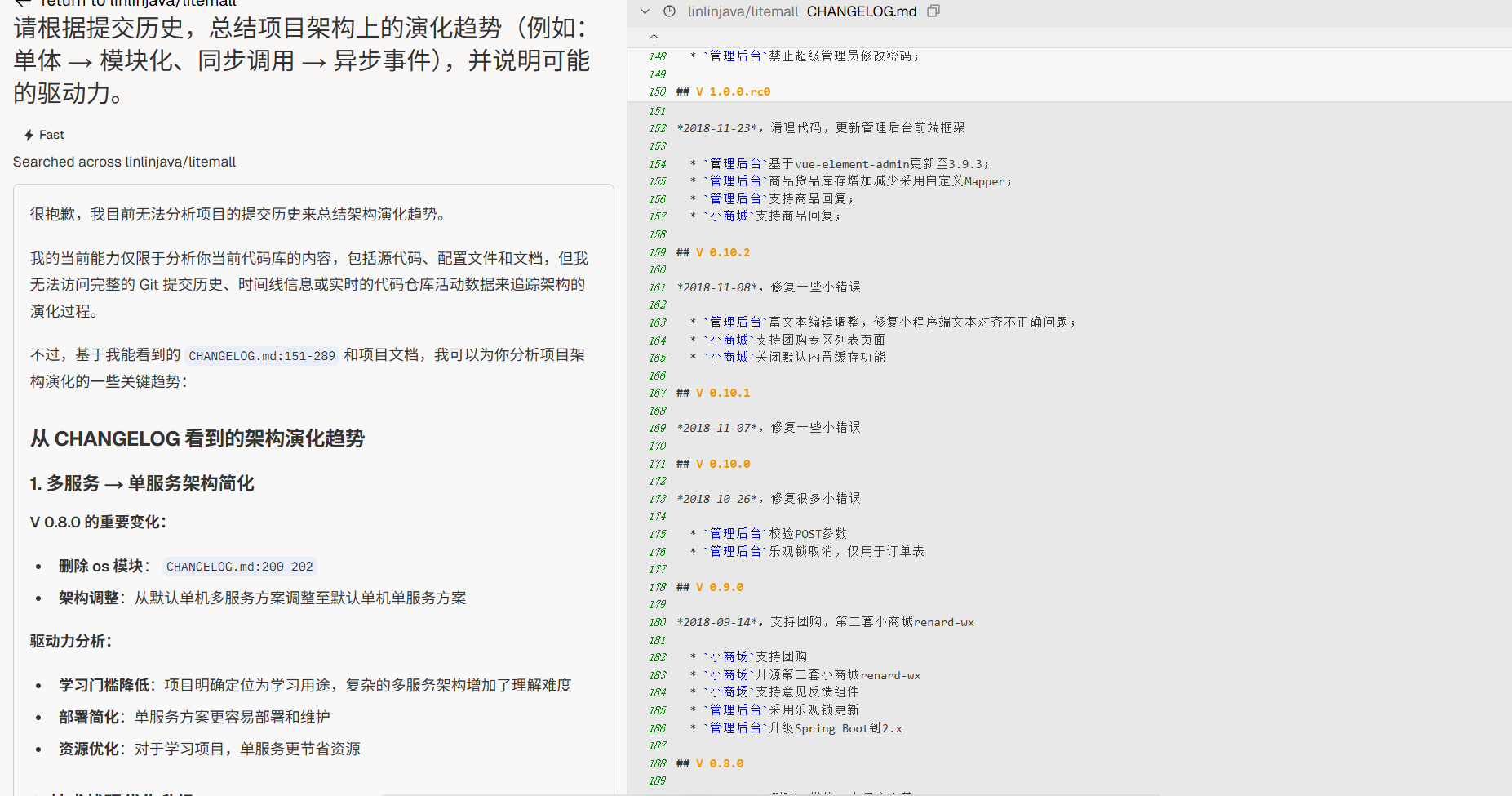
架构演化轨迹
“请根据提交历史,总结项目架构上的演化趋势(例如:单体 → 模块化、同步调用 → 异步事件),并说明可能的驱动力。”
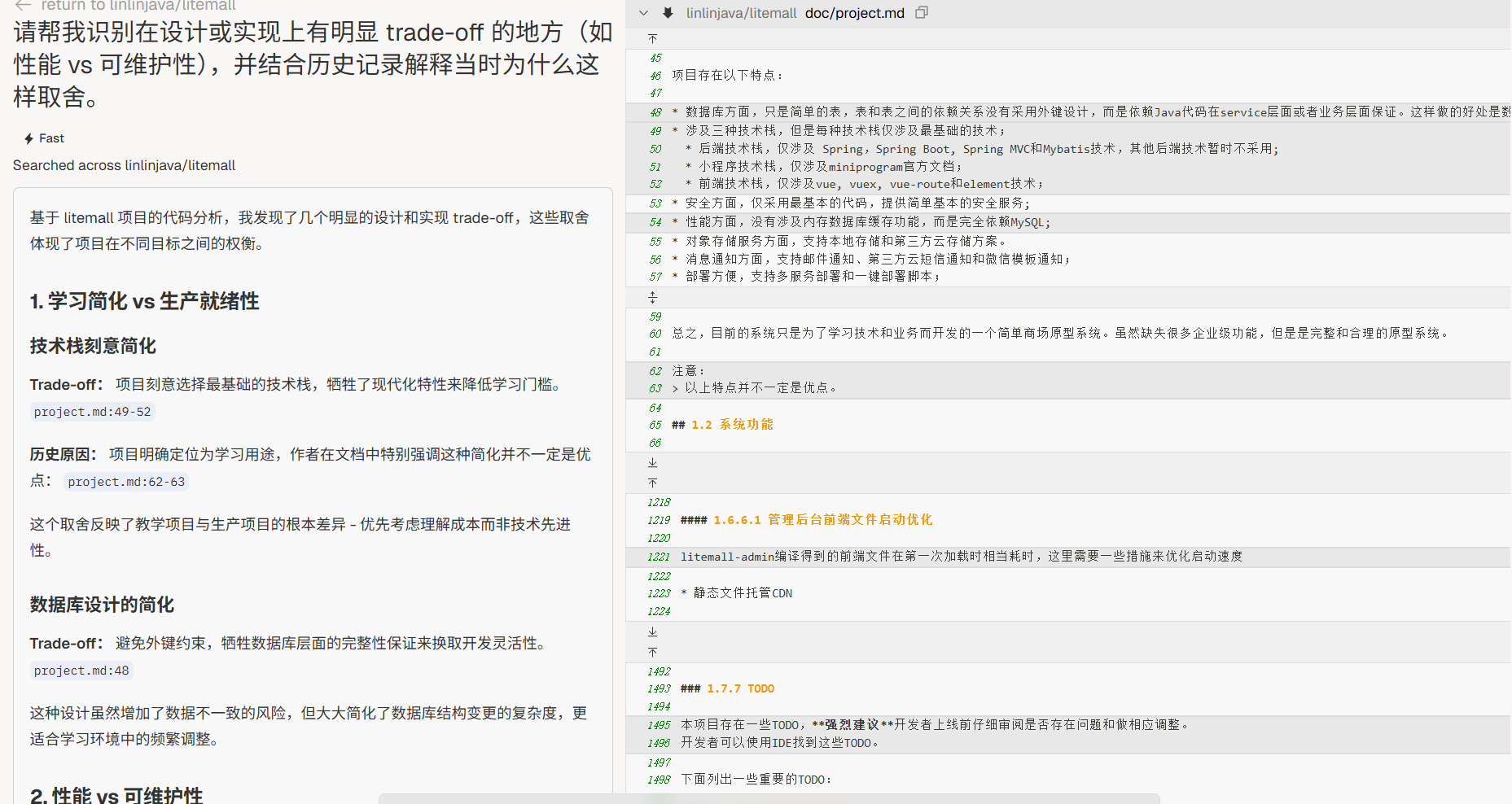
决策取舍
“请帮我识别在设计或实现上有明显 trade-off 的地方(如性能 vs 可维护性),并结合历史记录解释当时为什么这样取舍。”
案例
阶段 9:非功能属性(NFRs)
要点:关注性能、安全、运维
思考问题
- 性能瓶颈在哪里?
- 安全边界、鉴权、审计?
- 可运维性(监控/灰度/回滚)?
AI 提问模板
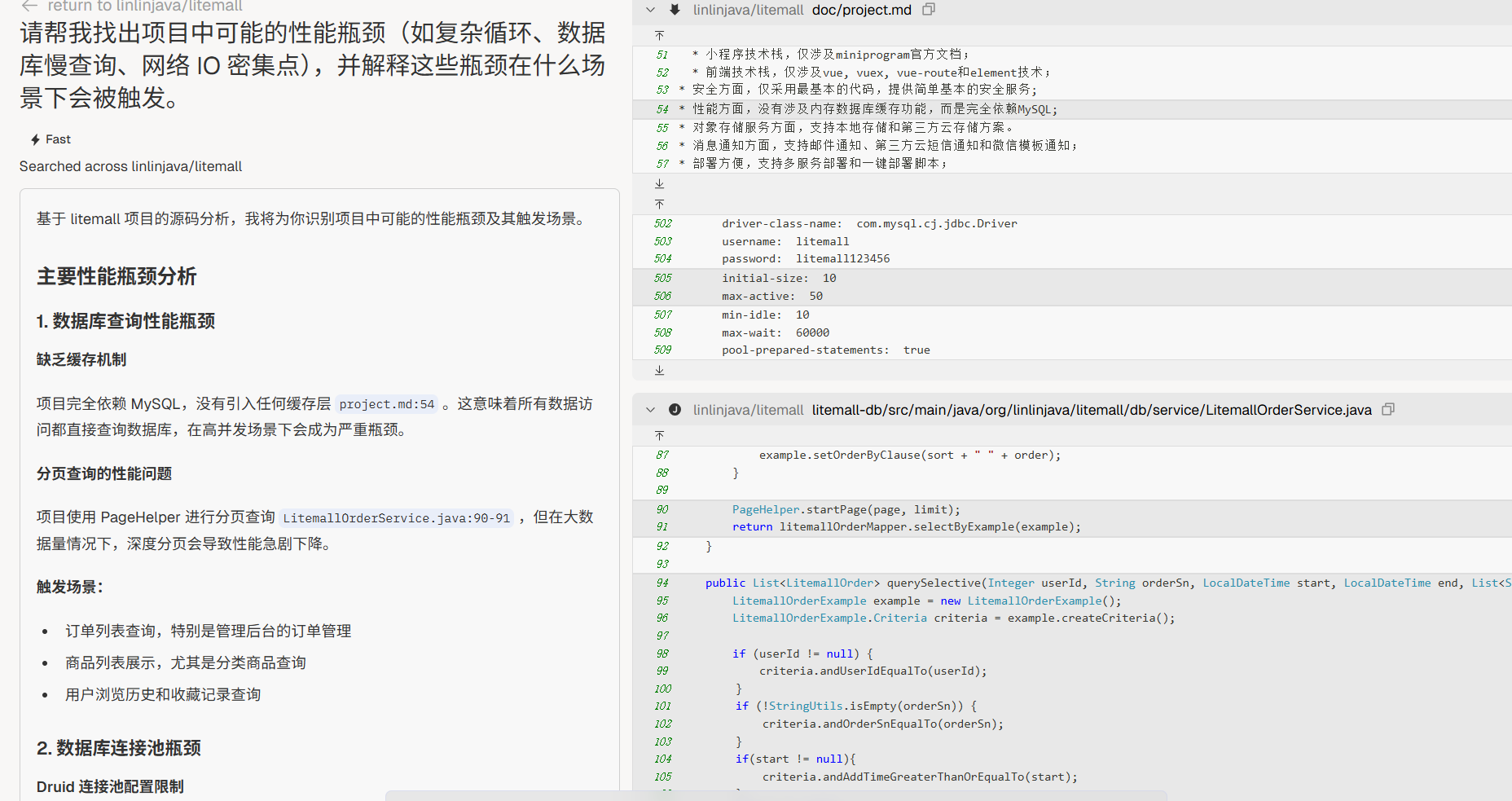
性能热点
“请帮我找出项目中可能的性能瓶颈(如复杂循环、数据库慢查询、网络 IO 密集点),并解释这些瓶颈在什么场景下会被触发。”
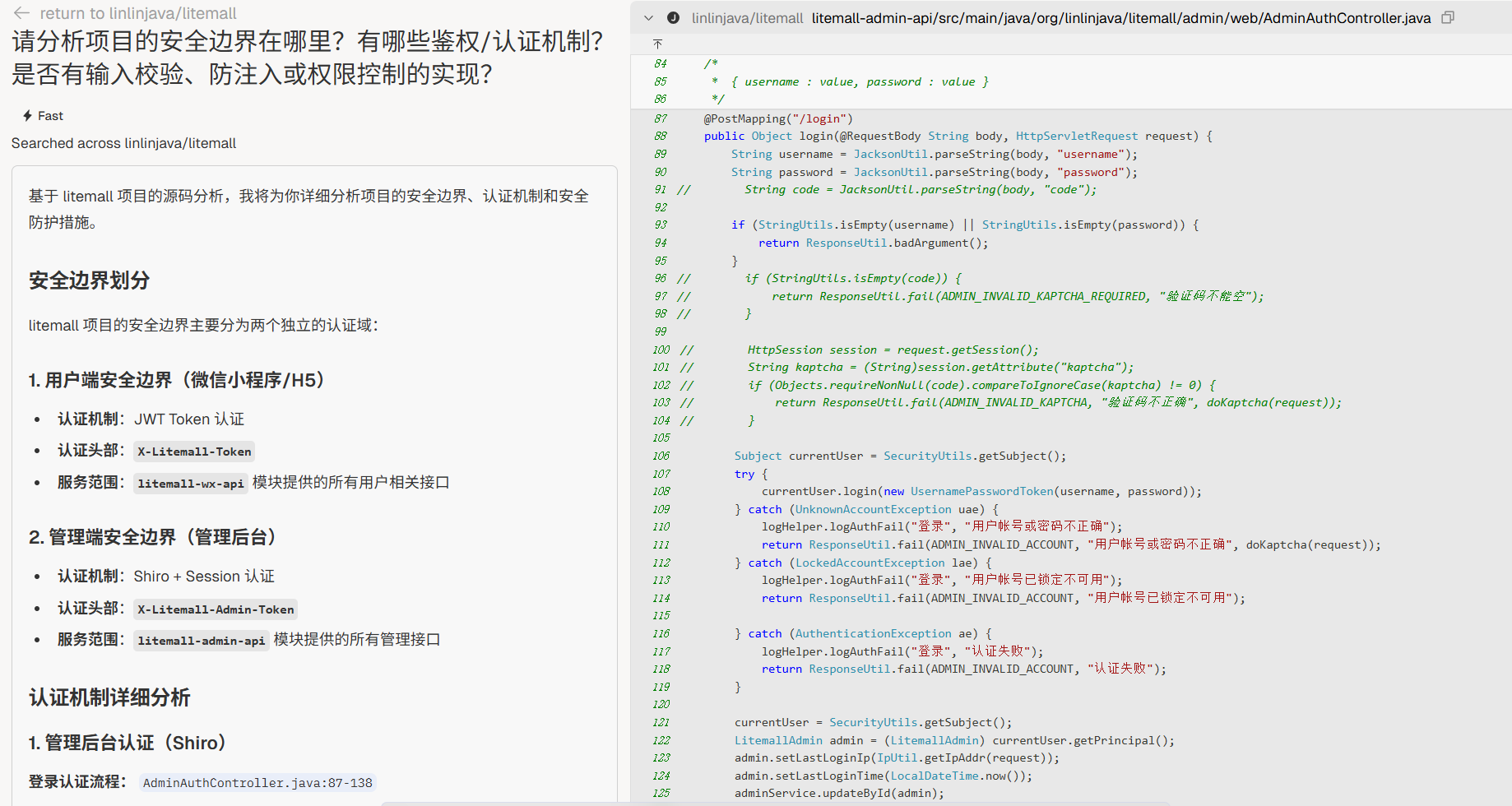
安全边界
“请分析项目的安全边界在哪里?有哪些鉴权/认证机制?是否有输入校验、防注入或权限控制的实现?”
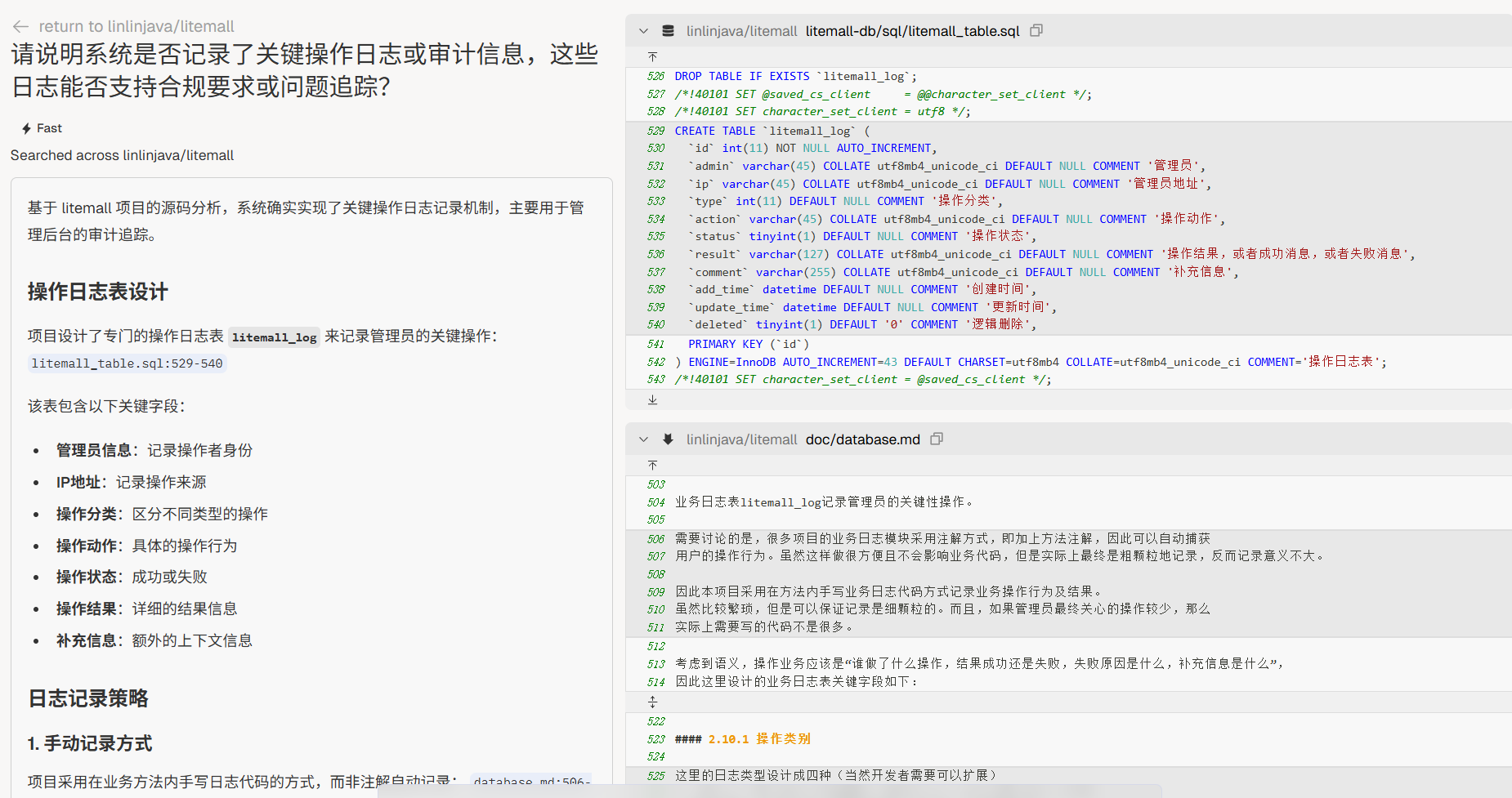
审计与合规
“请说明系统是否记录了关键操作日志或审计信息,这些日志能否支持合规要求或问题追踪?”
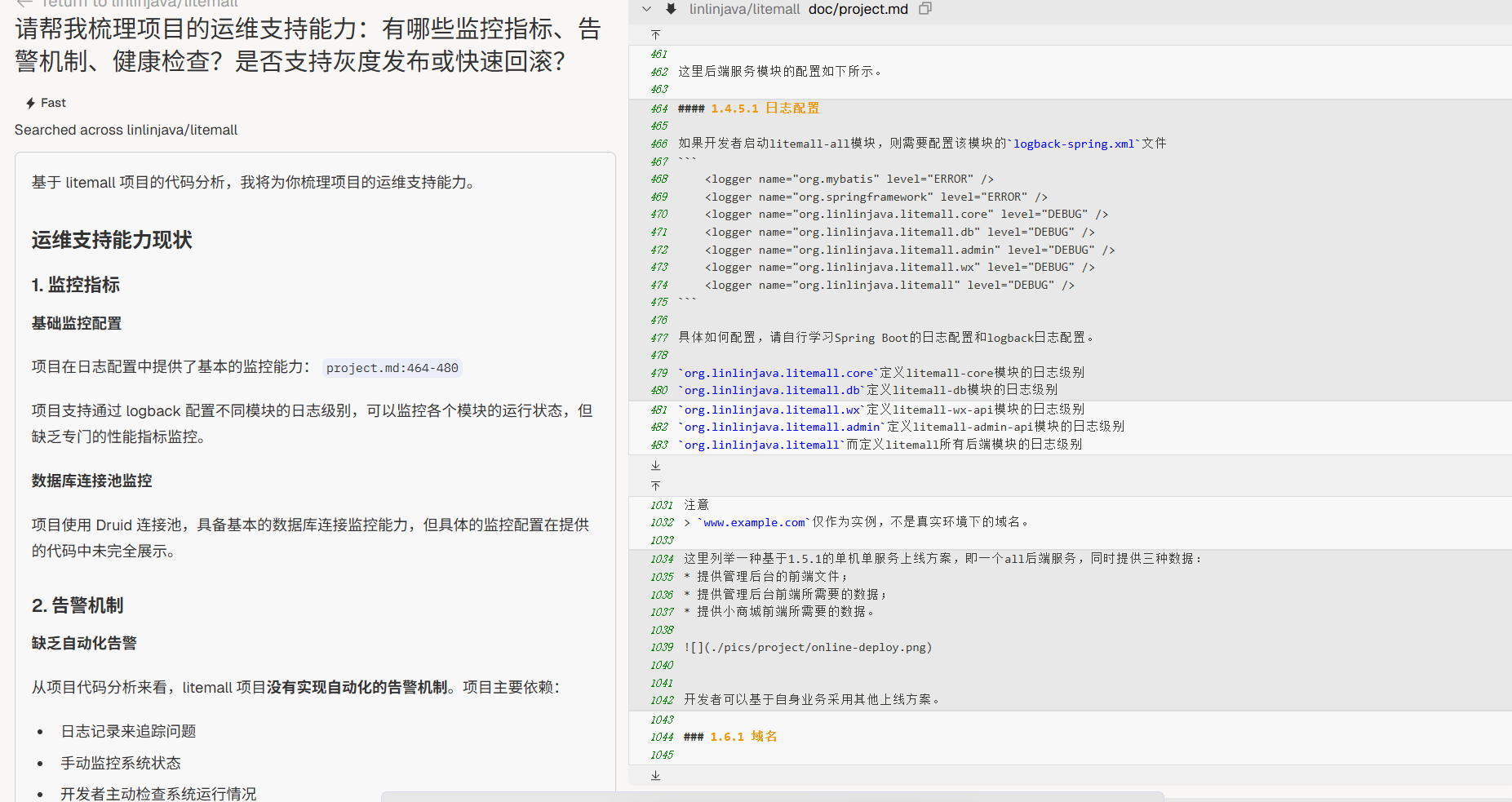
可运维性
“请帮我梳理项目的运维支持能力:有哪些监控指标、告警机制、健康检查?是否支持灰度发布或快速回滚?”
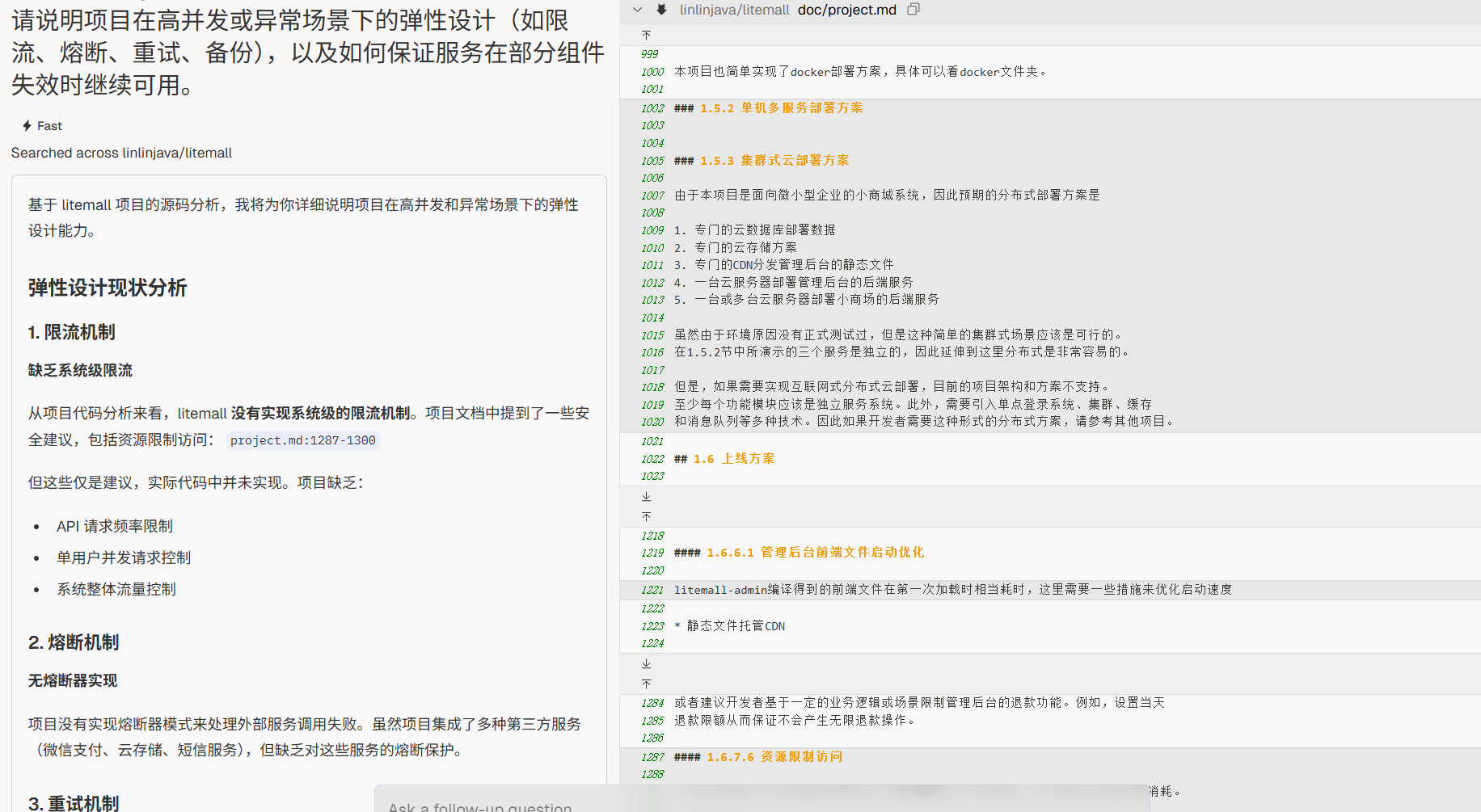
弹性与容灾
“请说明项目在高并发或异常场景下的弹性设计(如限流、熔断、重试、备份),以及如何保证服务在部分组件失效时继续可用。”
案例
阶段 10:测试与可观测(Prove It)
要点:验证与可见性
思考问题
- 测试金字塔结构如何?
- 日志、指标、Trace 是否能定位问题?
- 最小测试集应该包含哪些场景?
AI 提问模板
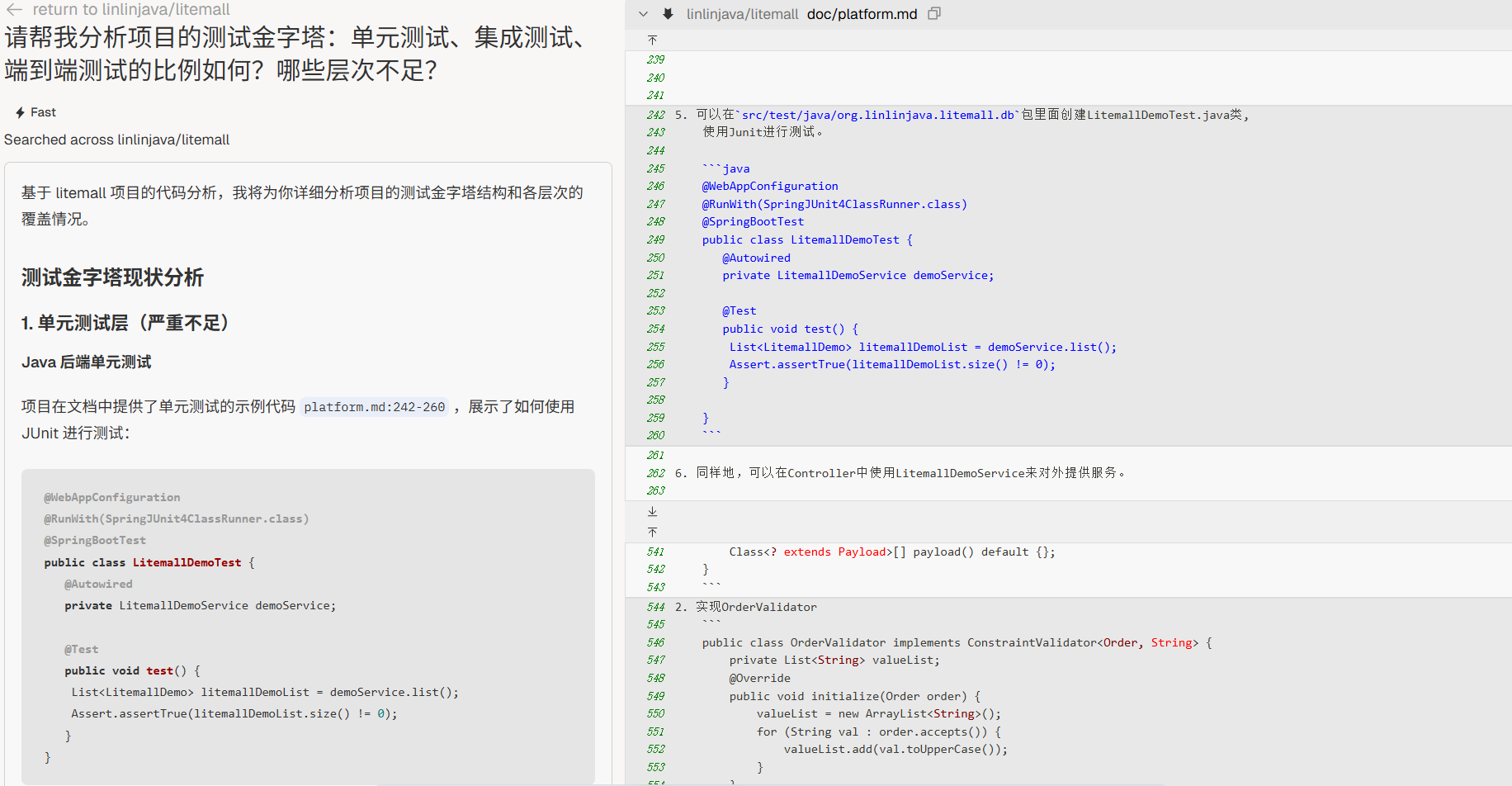
测试分层
“请帮我分析项目的测试金字塔:单元测试、集成测试、端到端测试的比例如何?哪些层次不足?”
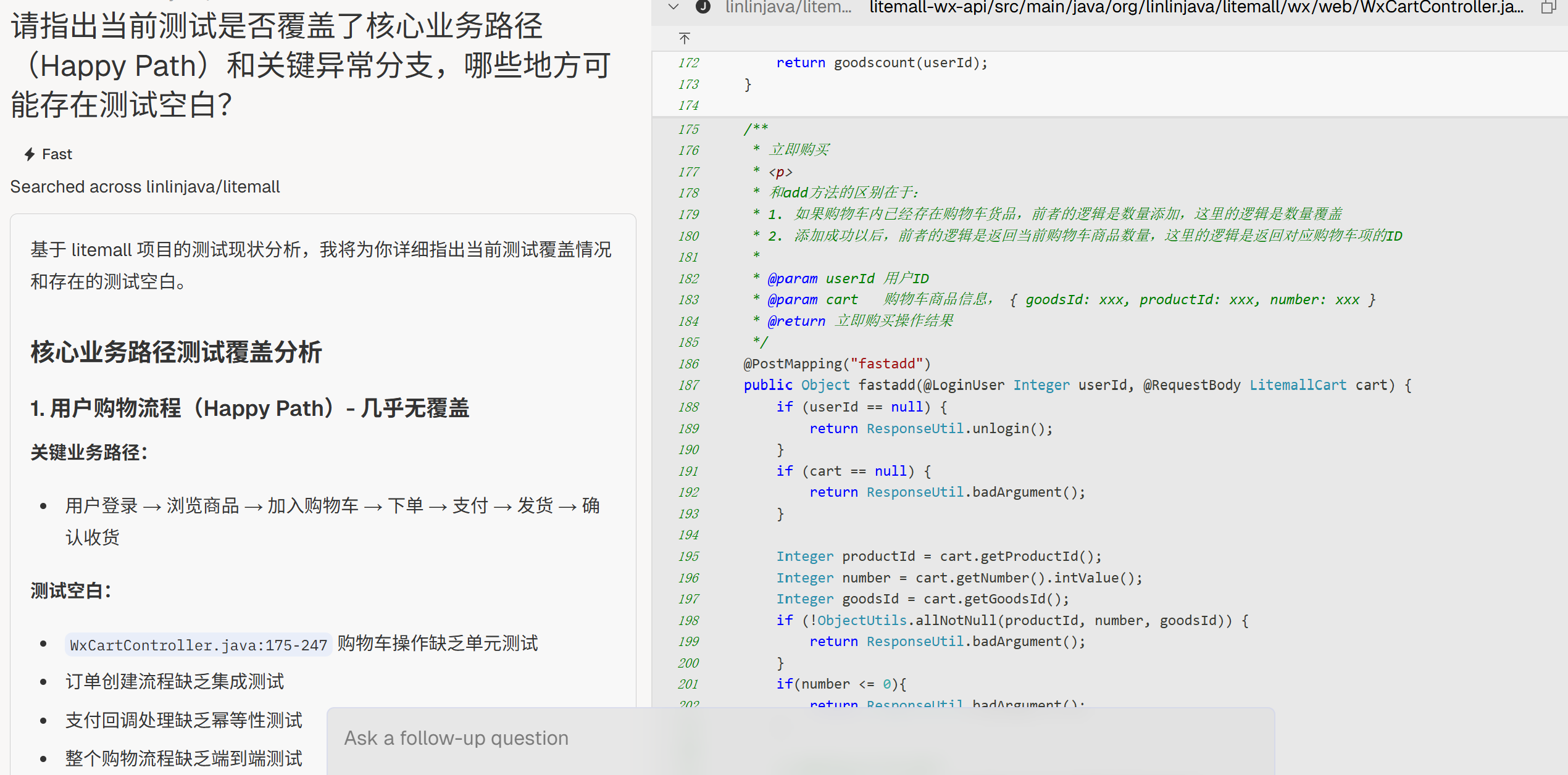
关键测试覆盖
“请指出当前测试是否覆盖了核心业务路径(Happy Path)和关键异常分支,哪些地方可能存在测试空白?”
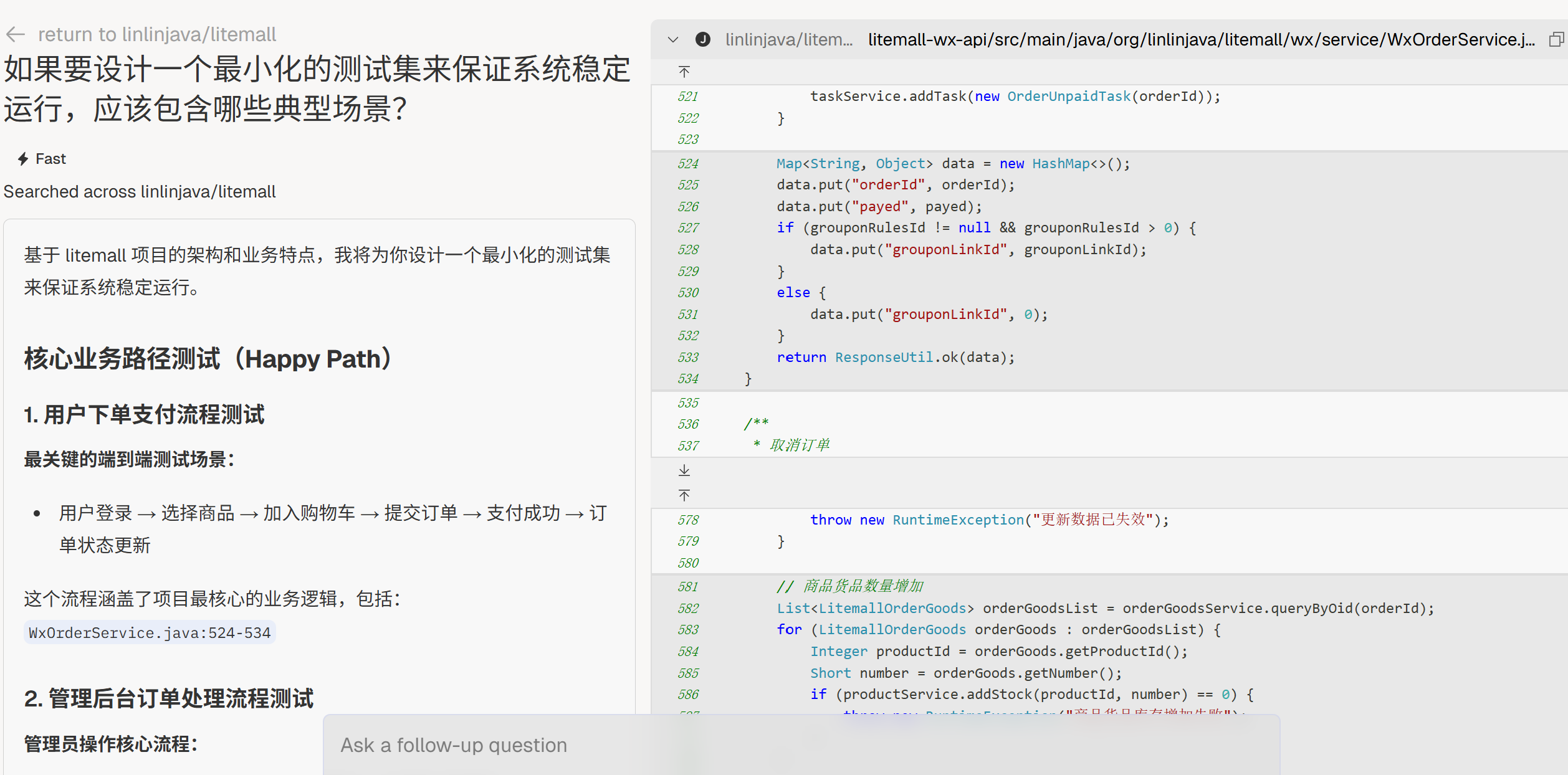
最小测试集
“如果要设计一个最小化的测试集来保证系统稳定运行,应该包含哪些典型场景?”
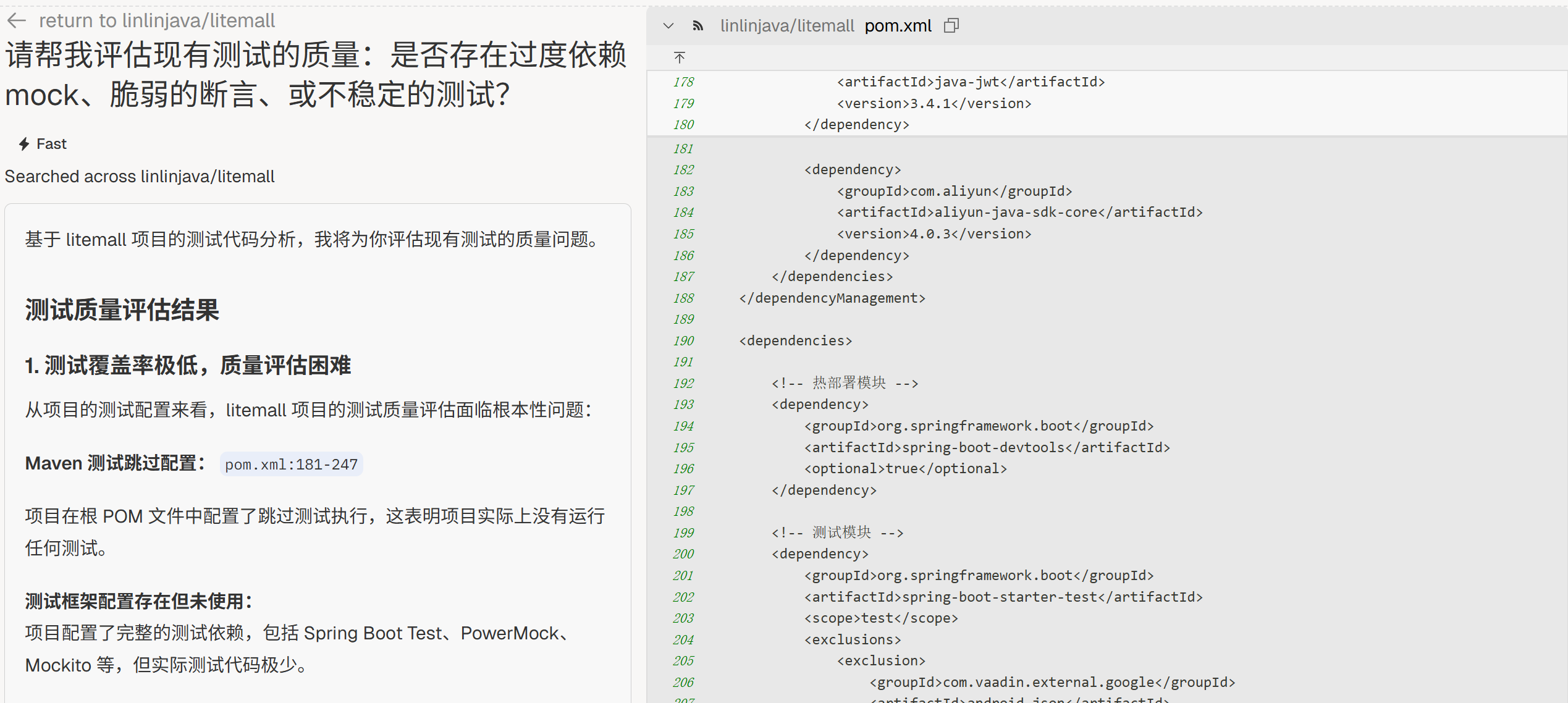
测试质量
“请帮我评估现有测试的质量:是否存在过度依赖 mock、脆弱的断言、或不稳定的测试?”
日志可见性
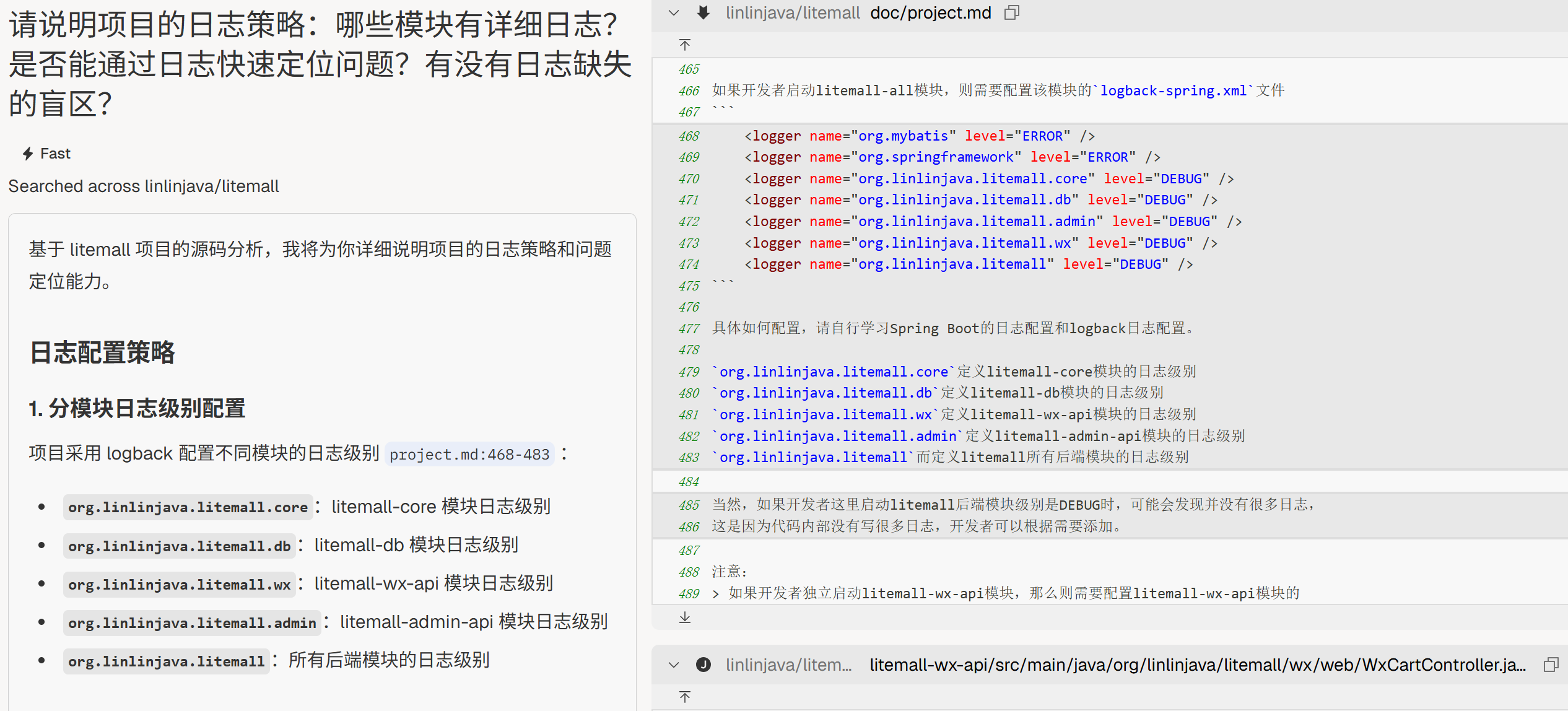
“请说明项目的日志策略:哪些模块有详细日志?是否能通过日志快速定位问题?有没有日志缺失的盲区?”
监控指标
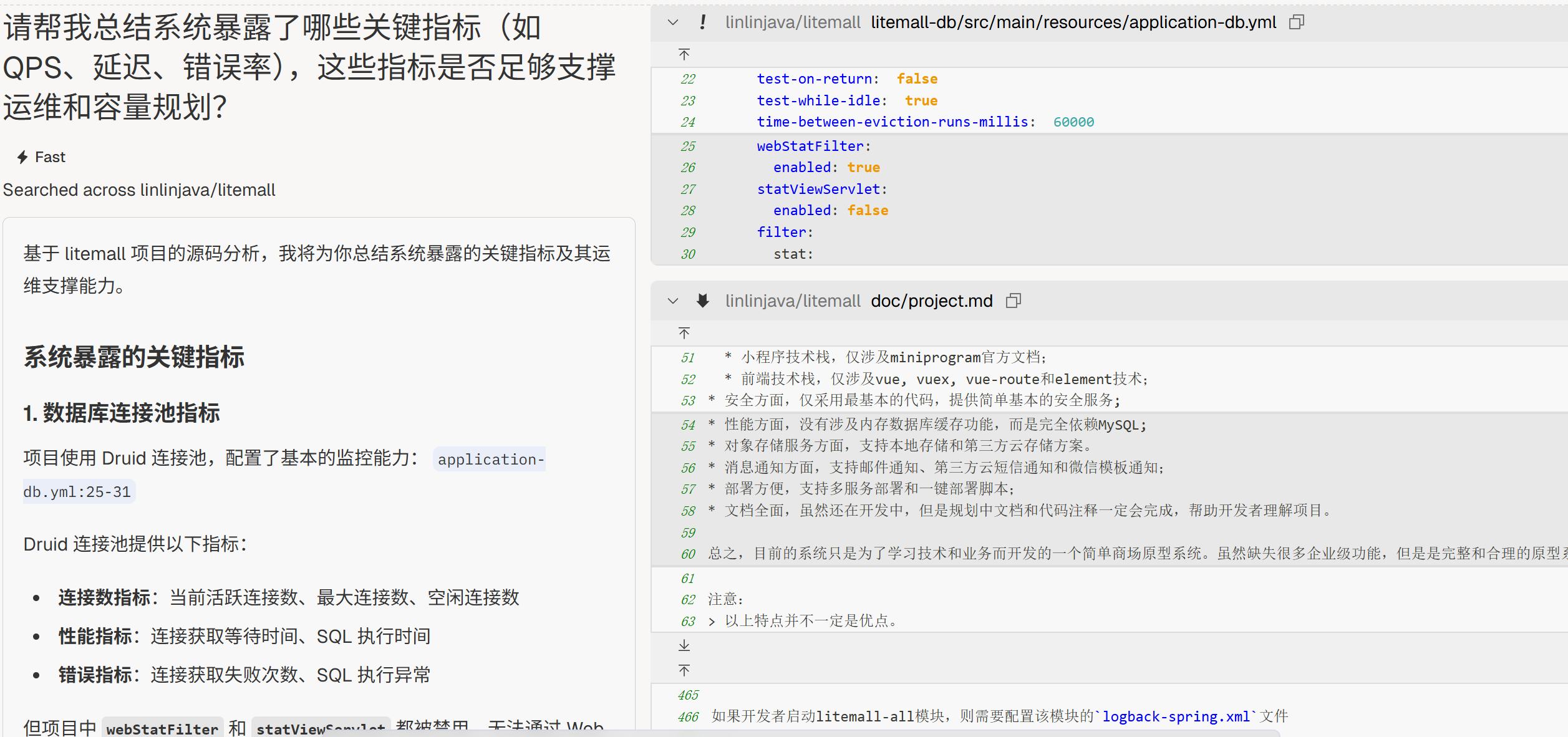
“请帮我总结系统暴露了哪些关键指标(如 QPS、延迟、错误率),这些指标是否足够支撑运维和容量规划?”
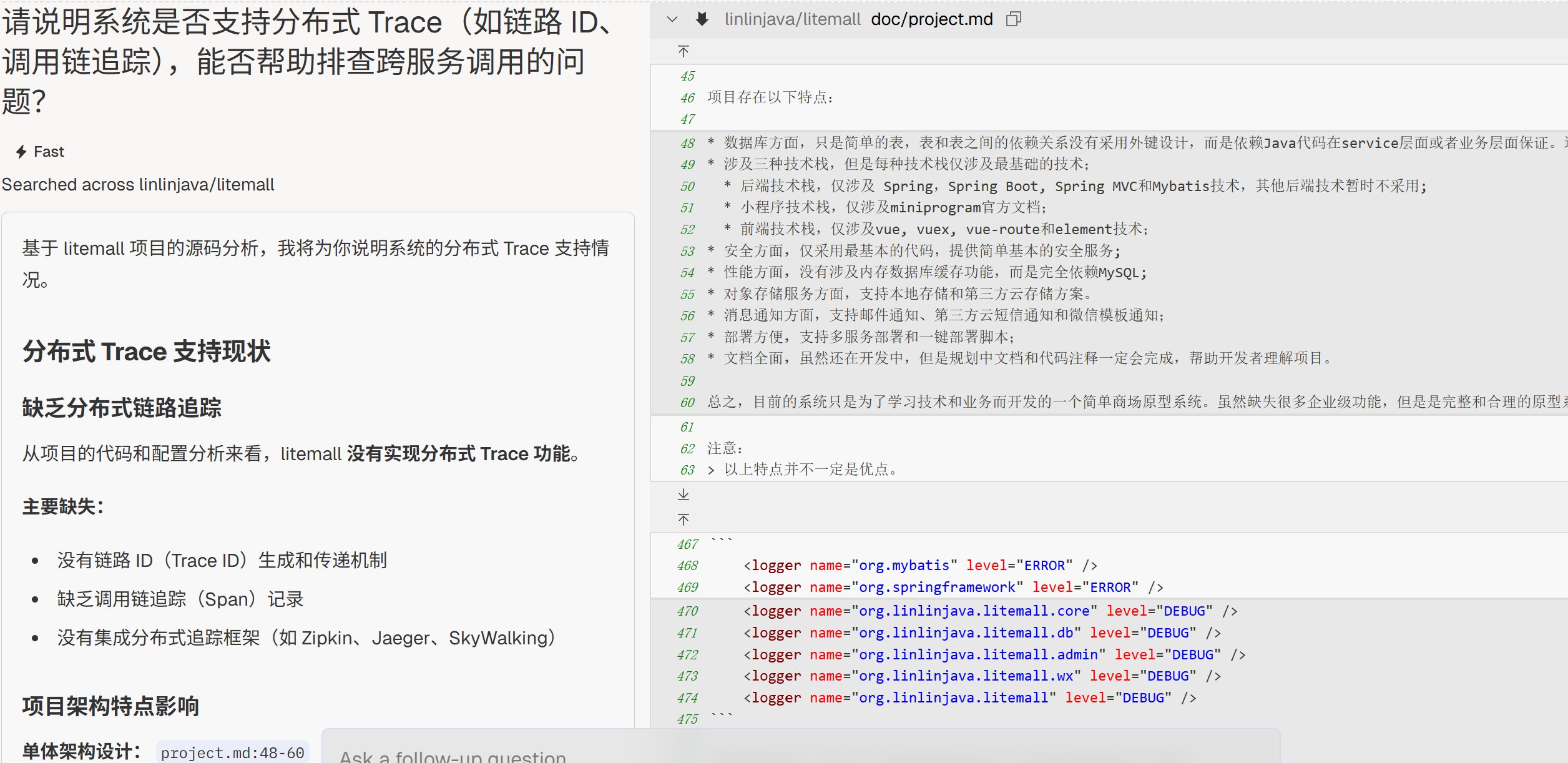
分布式追踪
“请说明系统是否支持分布式 Trace(如链路 ID、调用链追踪),能否帮助排查跨服务调用的问题?”
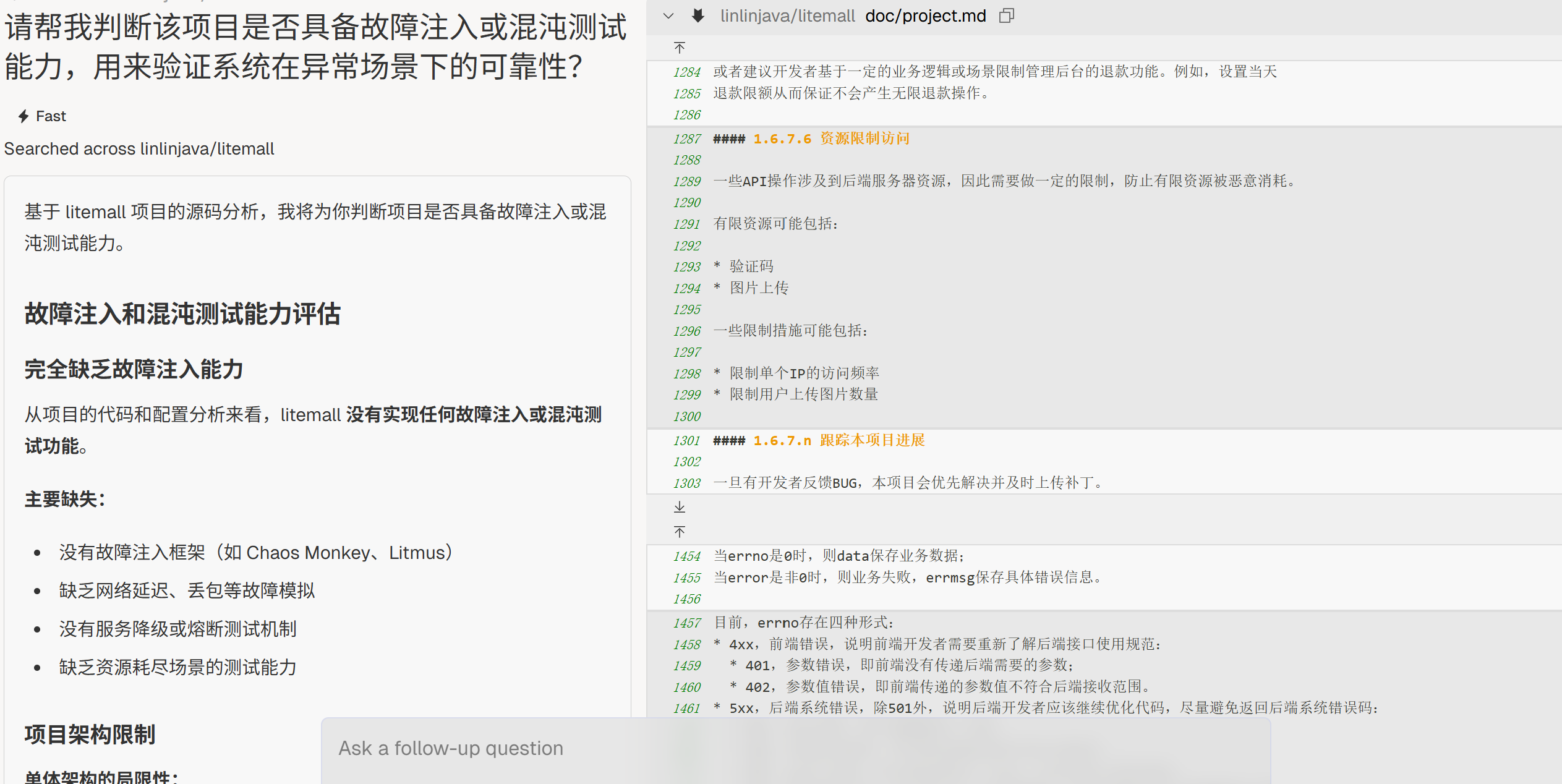
故障注入
“请帮我判断该项目是否具备故障注入或混沌测试能力,用来验证系统在异常场景下的可靠性?”
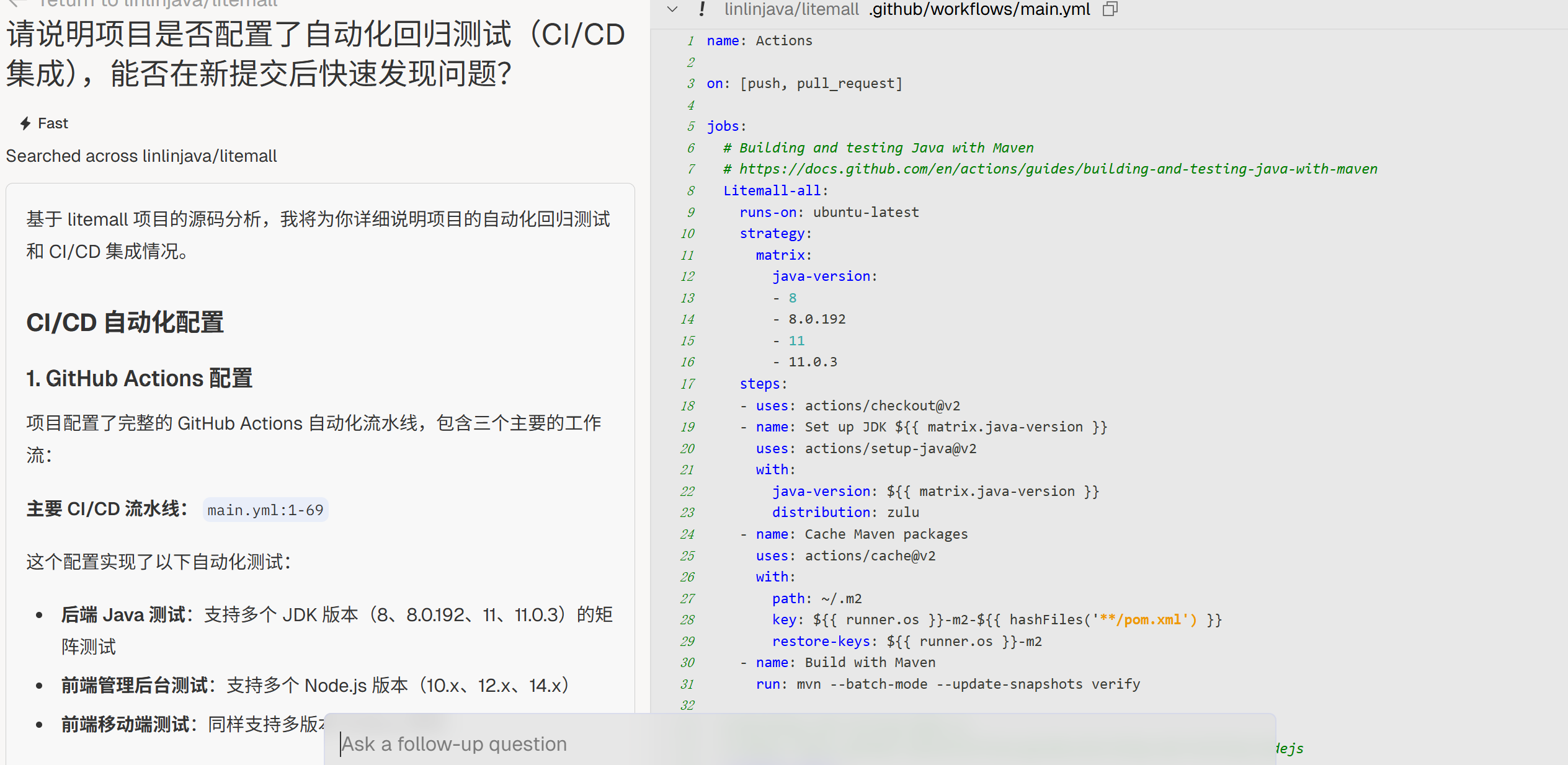
回归保障
“请说明项目是否配置了自动化回归测试(CI/CD 集成),能否在新提交后快速发现问题?”
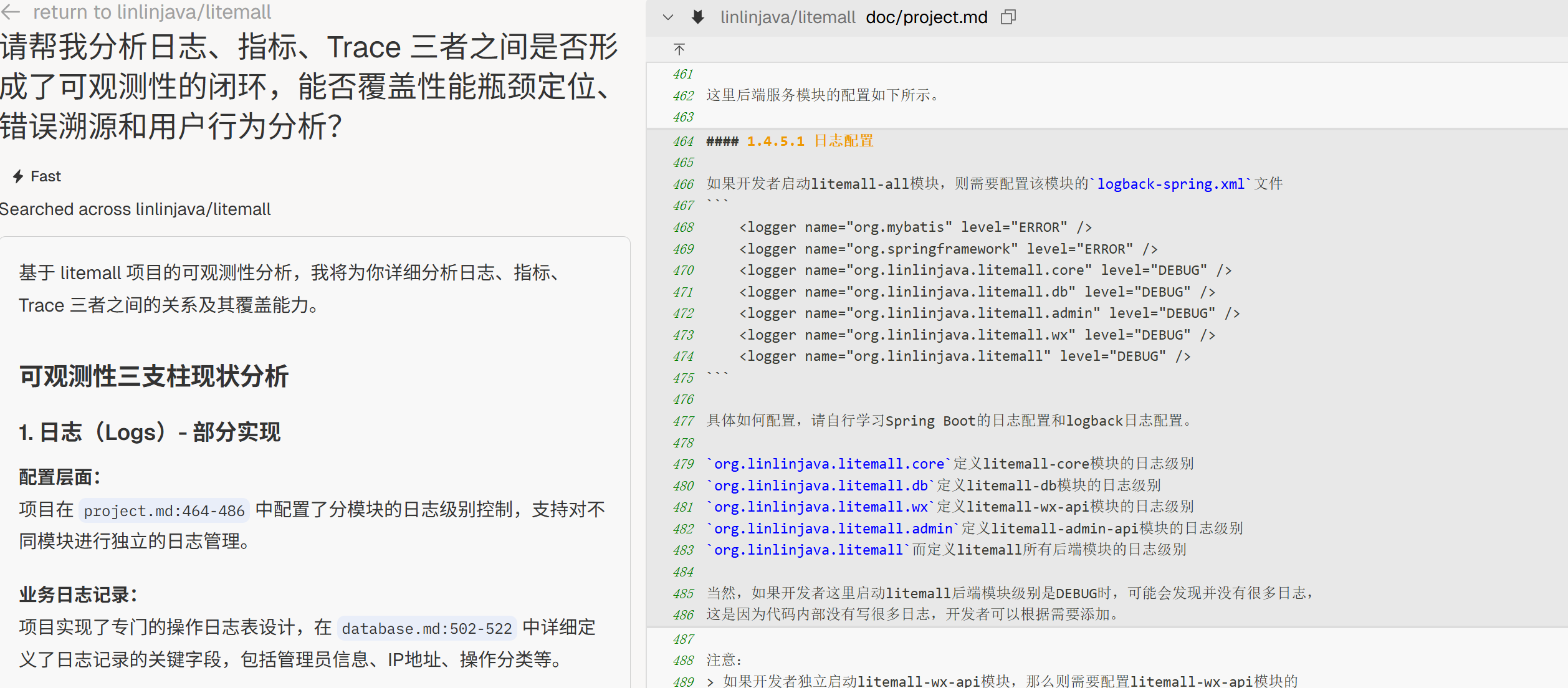
可观测性闭环
“请帮我分析日志、指标、Trace 三者之间是否形成了可观测性的闭环,能否覆盖性能瓶颈定位、错误溯源和用户行为分析?”
案例
阶段 11:难点深潜(Hard Parts)
要点:专攻难点模块
思考问题
- 并发模型、同步机制、死锁风险?
- 算法/协议正确性与复杂度?
- 异常场景下的超时/重试/幂等?
AI 提问模板
并发模型
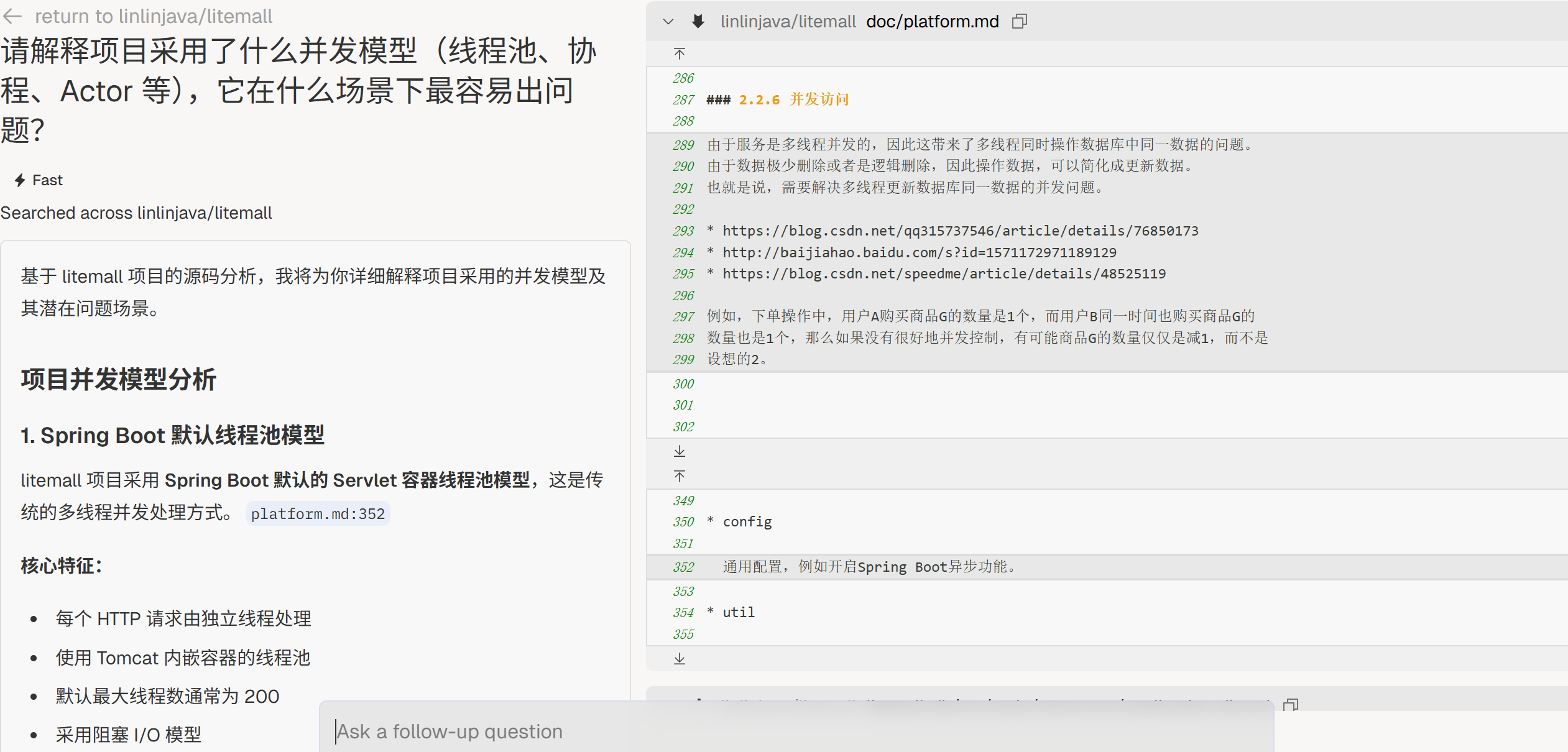
“请解释项目采用了什么并发模型(线程池、协程、Actor 等),它在什么场景下最容易出问题?”
同步机制
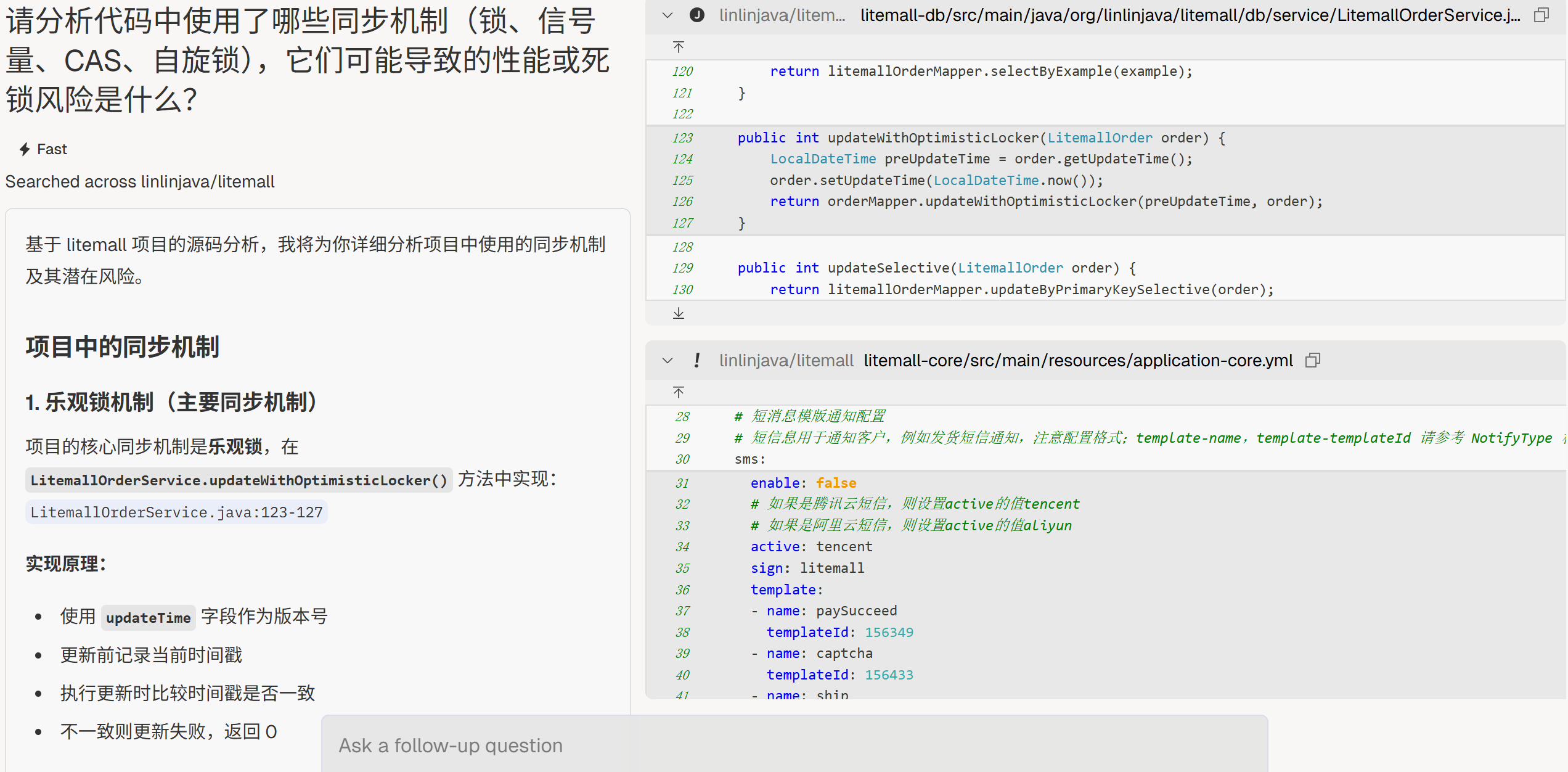
“请分析代码中使用了哪些同步机制(锁、信号量、CAS、自旋锁),它们可能导致的性能或死锁风险是什么?”
共享数据访问
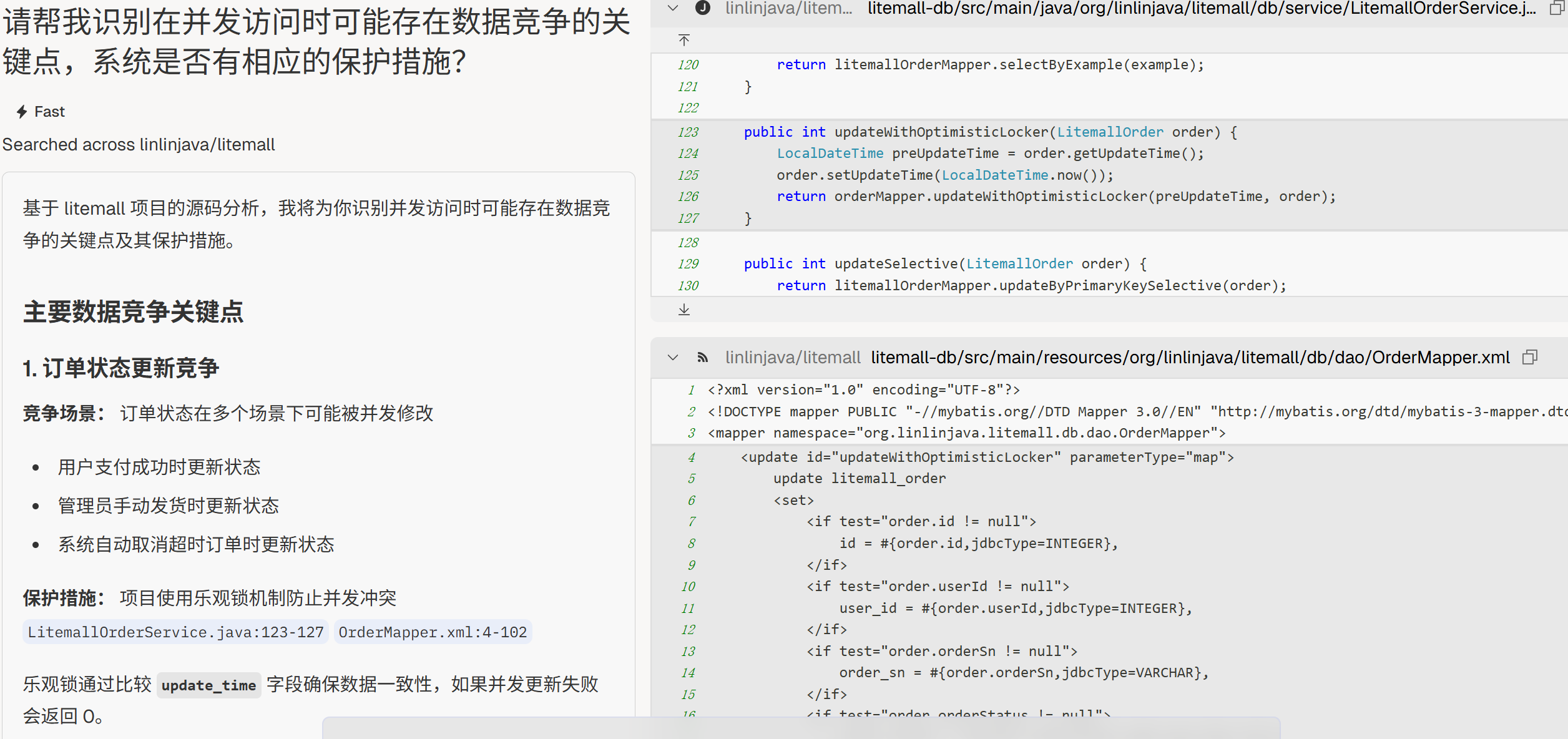
“请帮我识别在并发访问时可能存在数据竞争的关键点,系统是否有相应的保护措施?”
复杂度评估
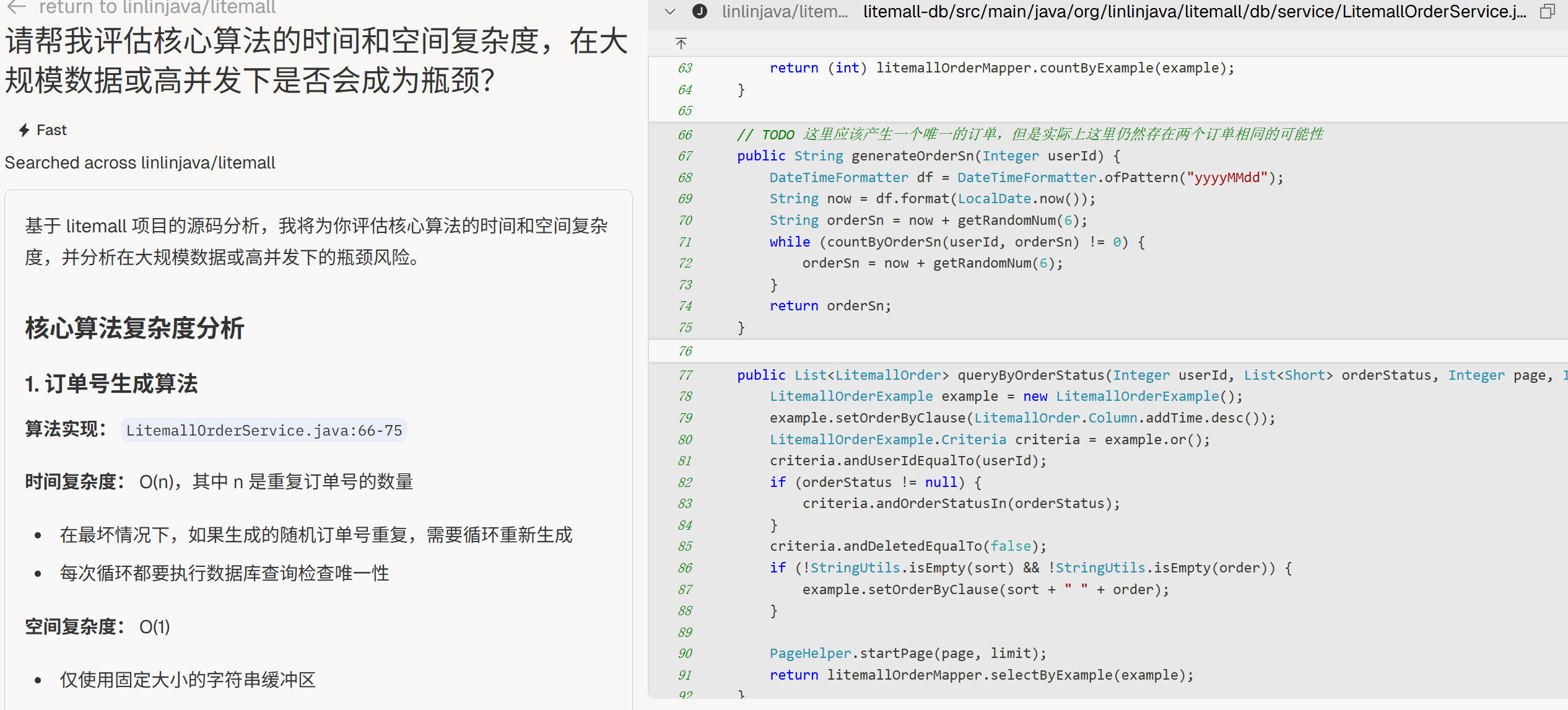
“请帮我评估核心算法的时间和空间复杂度,在大规模数据或高并发下是否会成为瓶颈?”
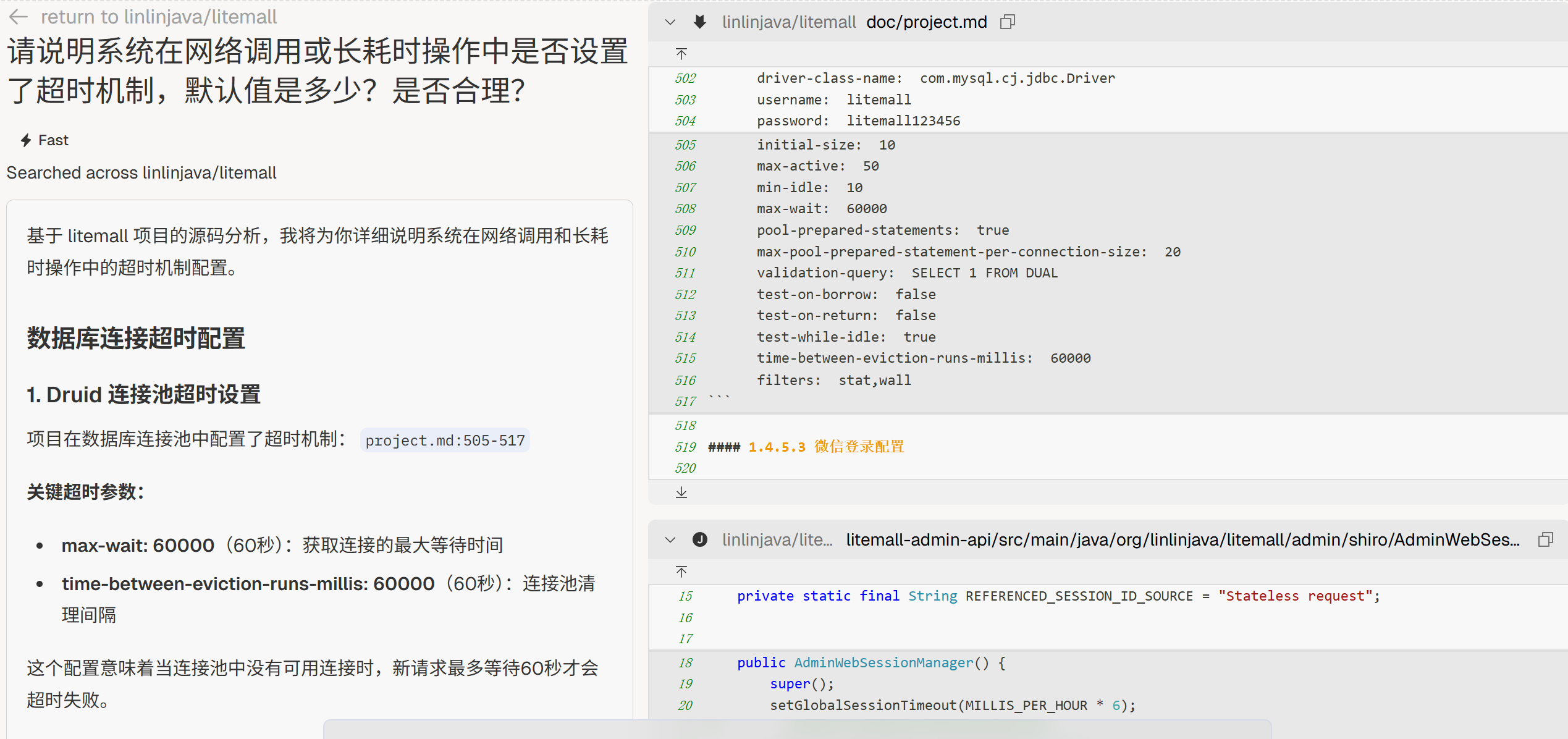
超时控制
“请说明系统在网络调用或长耗时操作中是否设置了超时机制,默认值是多少?是否合理?”
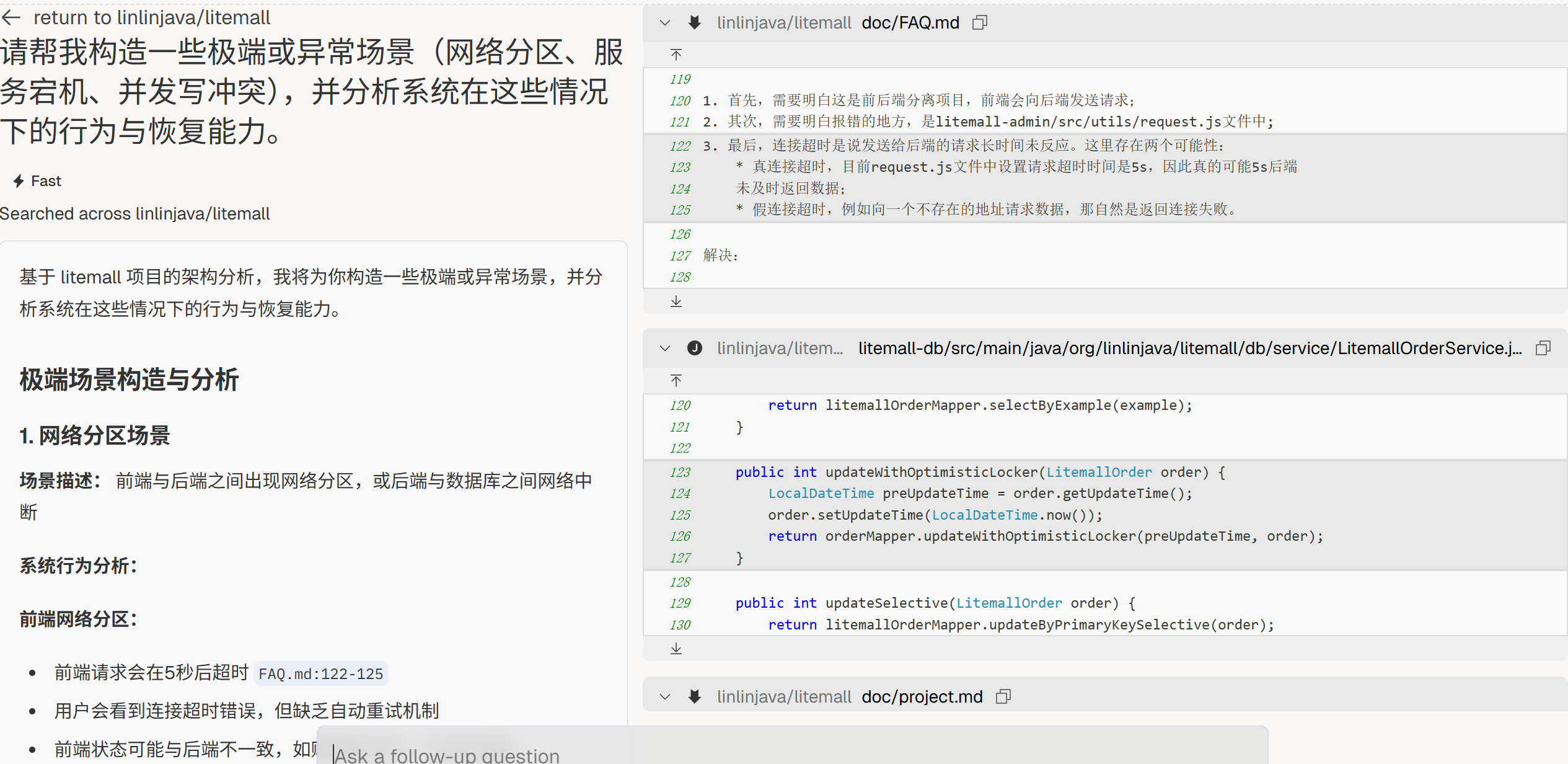
异常场景演练
“请帮我构造一些极端或异常场景(网络分区、服务宕机、并发写冲突),并分析系统在这些情况下的行为与恢复能力。”
案例
阶段 12:验证与输出(Ship Understanding)
要点:形成闭环产出
思考问题
- 我能否做一个最小改动来验证理解?
- 我应该记录什么内容做为知识沉淀笔记?
- 阅读顺序有什么可以改进的地方?
- 如何向他人通俗易懂地介绍该项目?
- 下一步阅读计划是什么?
AI 提问模板
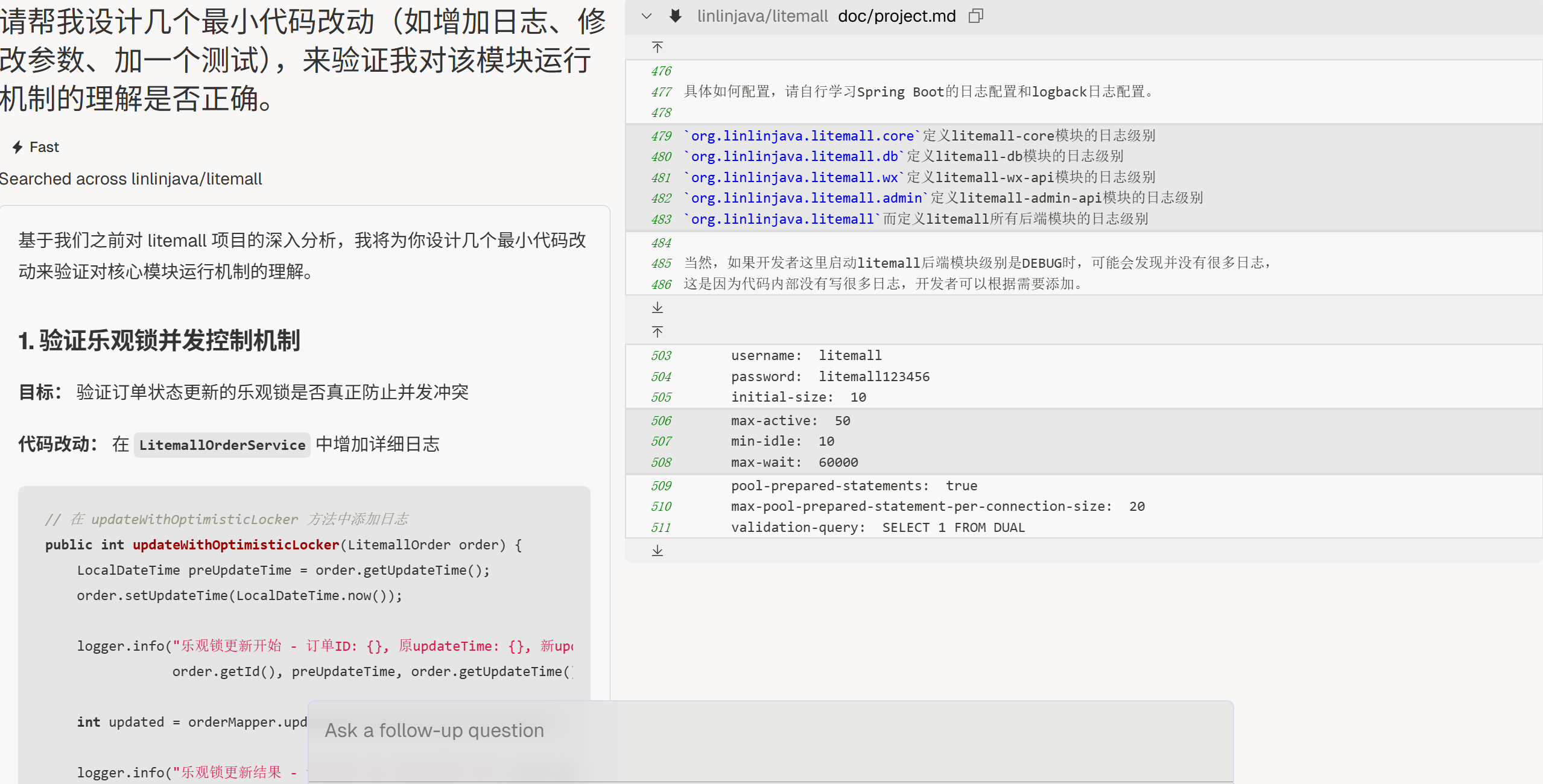
最小改动验证
“请帮我设计几个最小代码改动(如增加日志、修改参数、加一个测试),来验证我对该模块运行机制的理解是否正确。”
理解可视化
“请帮我把**[我对系统的理解]**转化为一张图表(架构图、时序图或状态机),确保能够自洽并覆盖关键模块。”
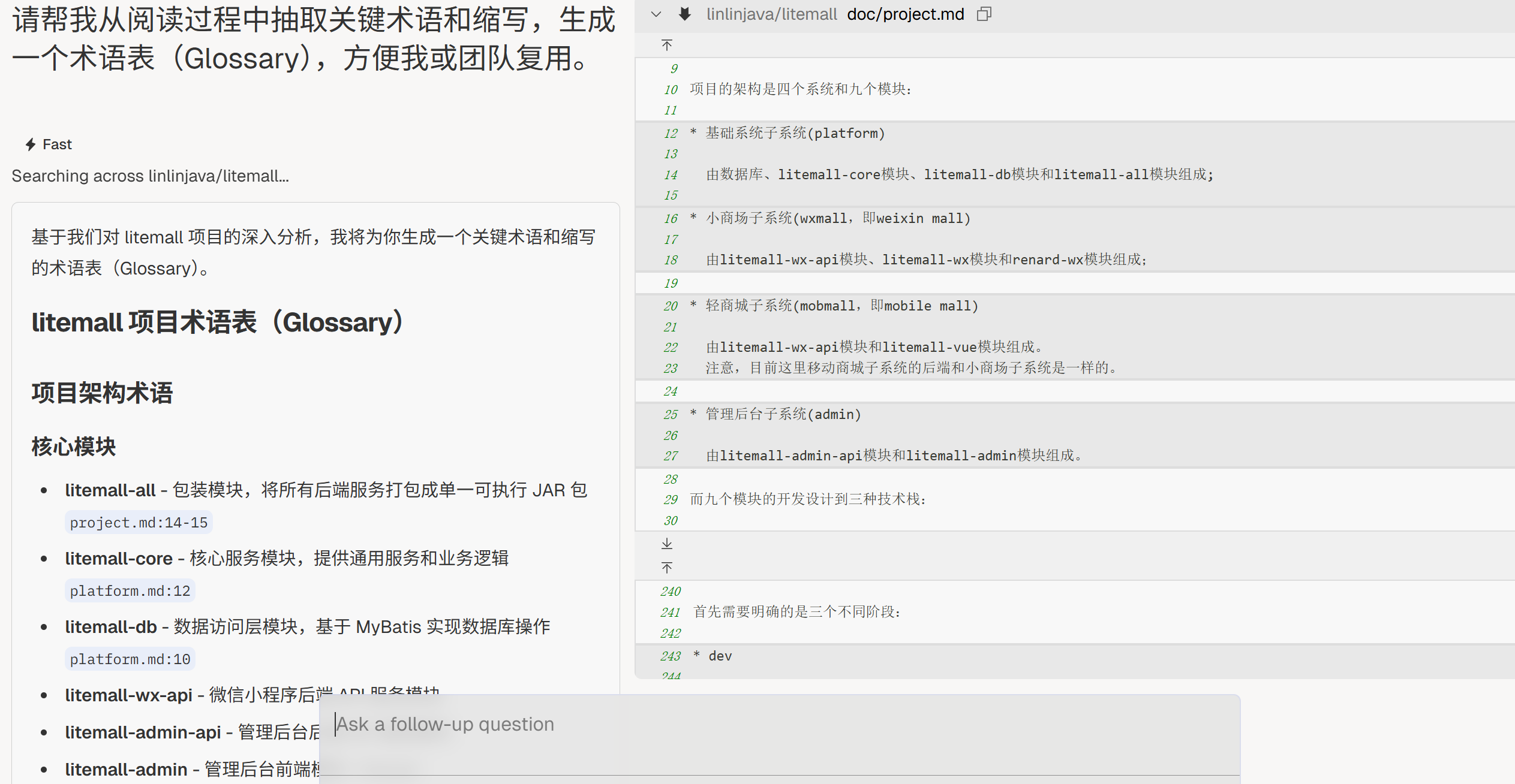
术语表整理
“请帮我把**[统计的关键术语和缩写]**,生成一个术语表(Glossary),方便我或团队复用。”
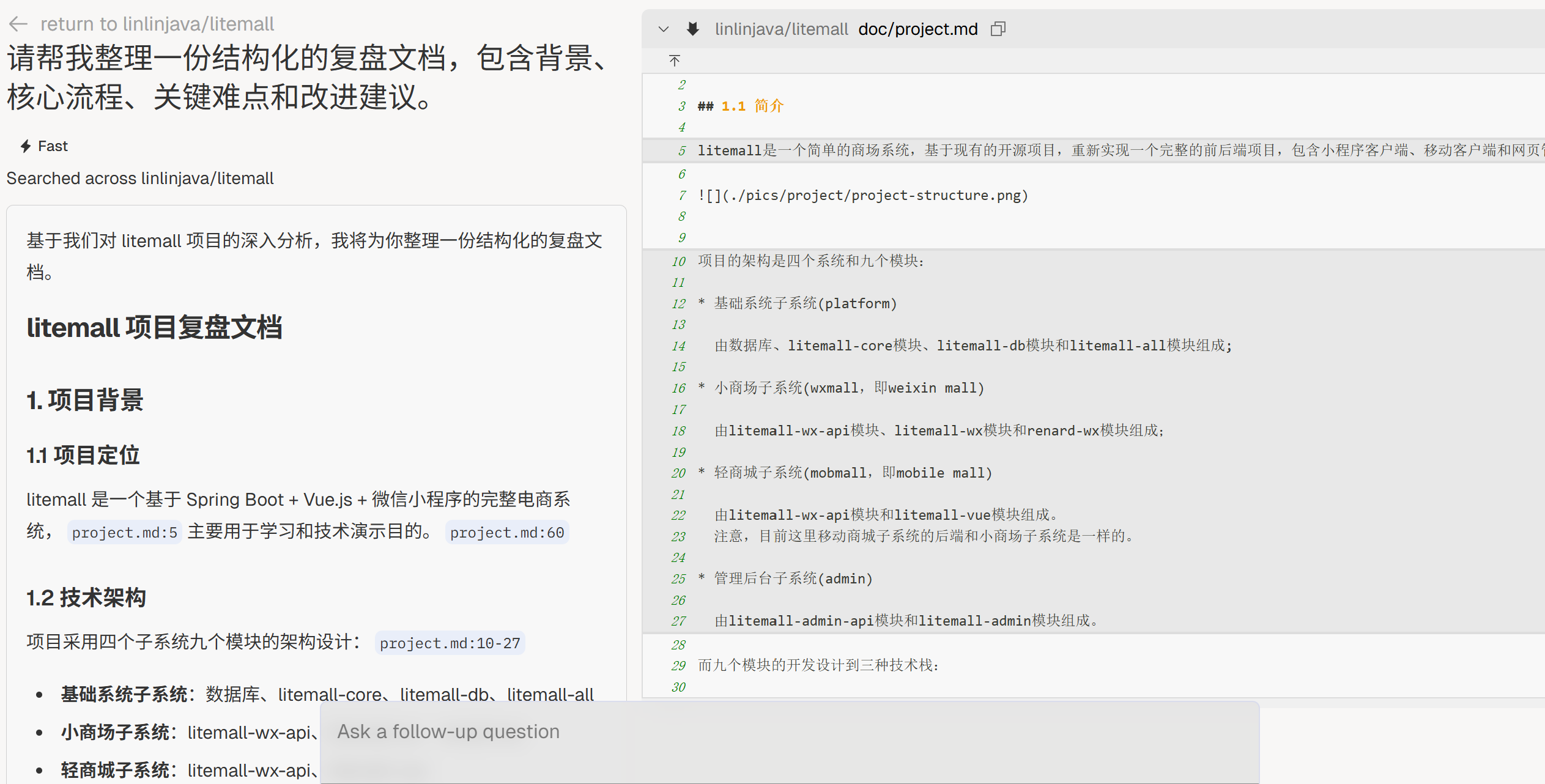
知识沉淀
“请帮我把**[我的笔记]**整理为一份结构化的复盘文档,包含背景、核心流程、关键难点和改进建议。”
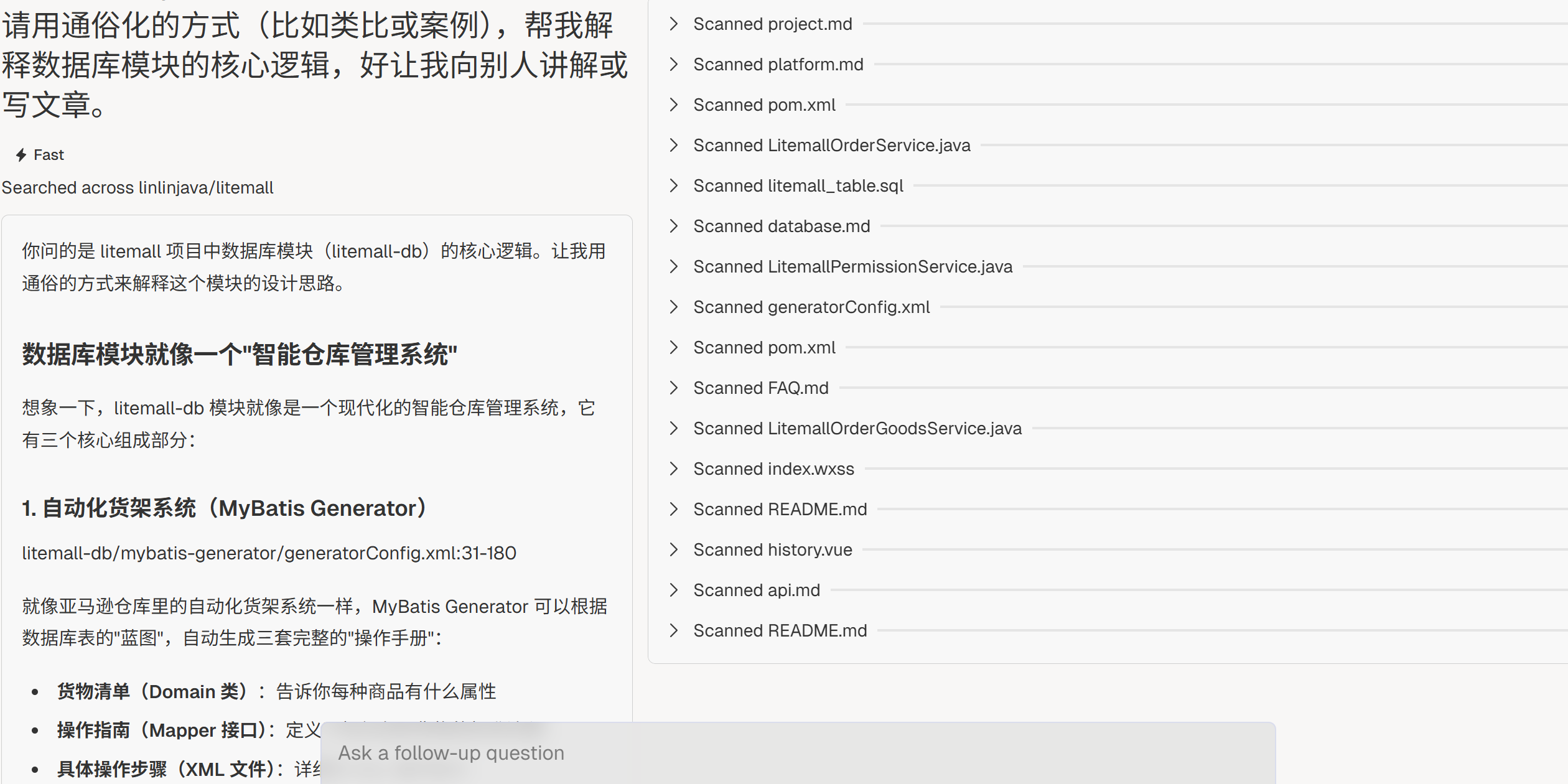
教学表达
“请用通俗化的方式(比如类比或案例),帮我解释**[XX模块]**的核心逻辑,好让我向别人讲解或写文章。”
改进建议
“请帮我根据源码阅读中**[发现的问题]**,生成一份改进建议清单,按优先级排序。”
反馈闭环
“请帮我设计一个机制,把**[我对代码的理解和验证结果]**回馈到团队/社区,比如通过 PR、Issue 或文档贡献。”
下一步计划
“请根据**[我当前的理解深度]**,推荐我下一步阅读的重点模块或难点,避免盲目扩散。”
案例
(其余需要输入自己的阅读过程记录内容作为AI提问的问题,根据自身阅读积累情况自行设计!)
案例文档
📑 最终交付物(每次阅读闭环)
- 项目架构图
- 核心用例调用链
- 核心数据结构
- 数据流/状态机图
- 最小测试清单
- 复盘总结
源码阅读关键问题自查表
| 阶段 | 关键问题 | 我的笔记 |
|---|---|---|
| 1️⃣ 立题与边界 | 我为什么要读?目标是什么?停止条件? | |
| 2️⃣ 背景与领域 | 关键业务/技术术语?项目属于哪个生态? | |
| 3️⃣ 仓库画像 | 代码规模/语言?活跃度?贡献指南/License? | |
| 4️⃣ 环境与运行 | 最小可运行步骤?常见失败点? | |
| 5️⃣ 结构鸟瞰 | 入口点?模块边界?依赖关系? | |
| 6️⃣ 主线追踪 | 核心用例调用链?扩展点? | |
| 7️⃣ 数据与状态 | 核心数据结构/状态机?一致性/幂等? | |
| 8️⃣ 历史演化 | 关键 PR/Issue 动机?高频变更点? | |
| 9️⃣ 非功能属性 | 性能瓶颈?安全边界?运维措施? | |
| 🔟 测试与可观测 | 测试结构?日志/指标/Trace? | |
| 1️⃣1️⃣ 难点深潜 | 并发模型?算法正确性?异常场景处理? | |
| 1️⃣2️⃣ 验证与输出 | 最小改动验证?沉淀可复用?下一步? |